Eric Jang'ın AlphaGo'yu Yeniden Kurmasını İzledim, Siz İzlemek Zorunda Kalmayın
Yayınlanma tarihi 2026-05-2518 dk okuma3,469 kelimeLisans CC BY-NC-SA 4.0artificial intelligencecomputer sciencewritingpersonalİçindekiler
Nisan ayında Eric Jang, AlphaGo Zero'yu sıfırdan yeniden kurmak için iki hafta harcadı ve sonucu autogo adıyla, uzun ve etkileşimli bir yazıyla birlikte internete koydu. Geçen hafta da Dwarkesh Patel ile öğrendikleri üzerine iki buçuk saatlik bir kara tahta dersine oturdu. Sohbeti bir arada tutan ana soru şu: Baskın paradigmanın policy-gradient RL ile eğitilmiş büyük dil modellerine kaydığı bir dünyada AlphaGo tarifi bize hala ne öğretebilir?
Bu yazı, konuşmadaki on kavramsal bloğu, anlatıldıkları sırayla ele alıyor. Kayıttan sonra Eric'in errata olarak yayımladığı önemli bir düzeltmeyi de dahil ediyorum. Amaç, AlphaGo'nun eğitim döngüsünü bu kadar zarif yapan şeyi, neden kimsenin bunu LLM'lere temiz biçimde taşıyamadığını ve AlphaGo açısından bakınca bugünkü RL'in sınırlarının nasıl göründüğünü anlamak.
Başlığın ima ettiğinin aksine, bu tür işlerle ilgileniyorsanız podcast bölümünü izlemenizi öneririm.
1. Kaba kuvvet arama Go'da neden ölür?
Go, Tromp-Taylor puanlaması altında alan hesabıyla karara bağlanır. Bilgisayar bilimcilerin kullandığı kural seti genelde budur, çünkü oyunun ne zaman bittiği konusunda belirsizlik bırakmaz. Bu kulağa olduğundan daha önemli geliyor: AI için terminal state'lerde temiz bir reward sinyali vardır. İnsan profesyonel oyununda bu yoktur, çünkü insanlar istifa eder.
19×19 bir tahtada açılışta en fazla 361 legal hamle vardır. Taşlar hareket etmediği için branching factor her ply'de bir azalır. Tromp-Taylor altında oyunlar yaklaşık 300 ply sürer. Bu yüzden naif oyun ağacının yaklaşık
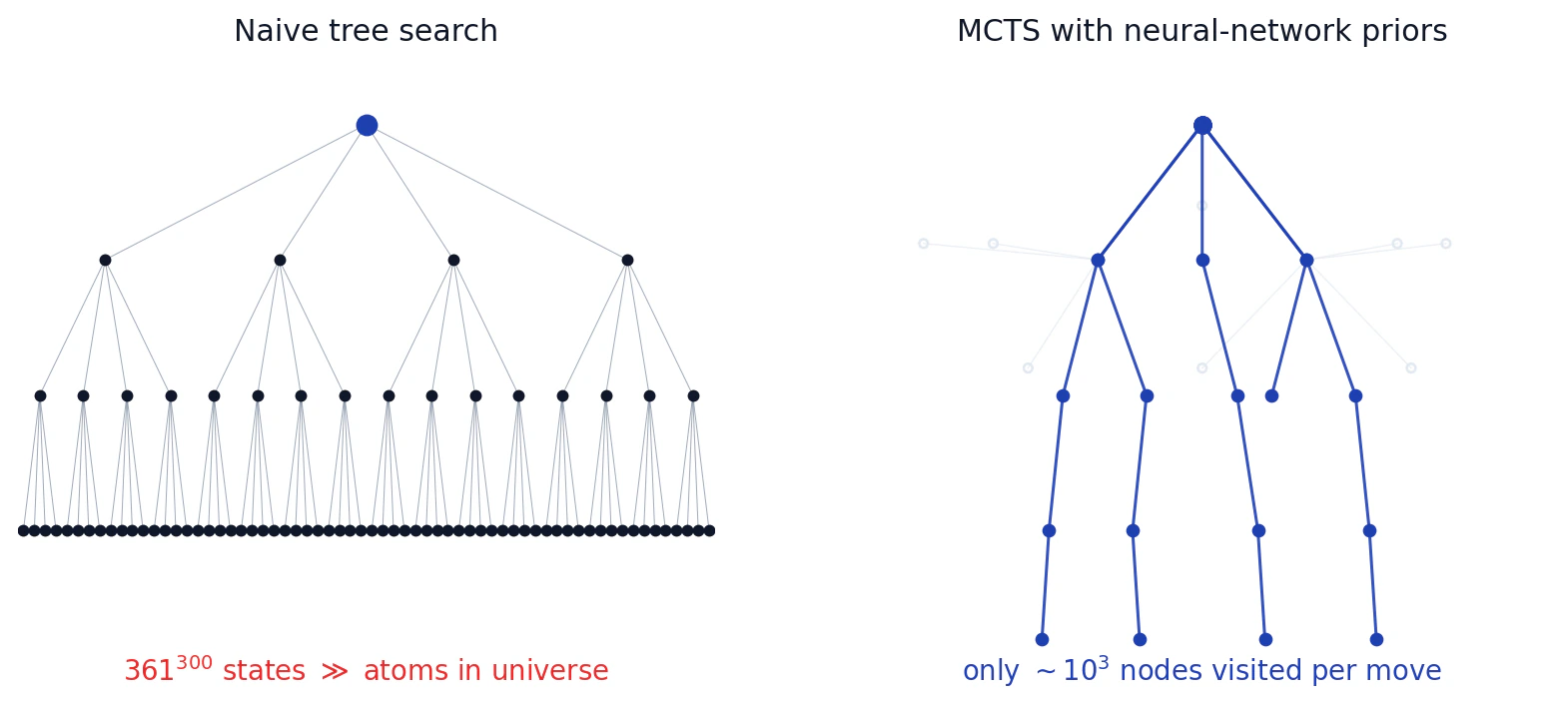
Sıfırdan başlayan herhangi bir Go programının karşılaştığı durum bu. Sayıp bitiremezsiniz. Hangi dalların araştırmaya değer olduğuna karar vermeniz gerekir. Eric, AlphaGo'nun kırılma noktasını birbirine bağlı iki soruya uygulanabilir bir cevap olarak çerçeveliyor: Ağacın genişliğini nasıl budarsınız, yani hangi hamleleri düşünmeye değer görürsünüz? Ve ağacın derinliğini nasıl budarsınız, yani ne zaman simülasyonu durdurup ortaya çıkan pozisyonun değerini tahmin edersiniz?
AlphaGo'dan önce klasik Monte Carlo Tree Search bu ilk soruyu UCB1 (Upper Confidence Bound 1) ile ele alıyordu. Bu, şu ifadeyi maksimize eden child node'u seçen bir multi-armed-bandit sezgiseli:
Veri yapılarını anlamak için netleştirmem gereken birkaç tanım:
- root node: tahtanın mevcut state'i.
- children: root'tan bir legal hamleyle ulaşılabilen state'ler.
: bu edge üzerinden ulaşılan leaf'lerin ortalama değeri. : state'inde action'ını alma olasılığı. Bu ancak policy network geldiğinde devreye girer.
İlk terim exploit terimidir; bu edge üzerinden ulaşılan leaf değerlerinin online running mean'idir. İkinci terim explore bonus'udur; parent'ın visit count'u
Sorun şu: UCB1'in hangi child'ların a priori ziyaret etmeye değer olduğuna dair hiçbir fikri yoktur. 361 aday hamle varken, erken aşamada aptal hamleleri de umut veren hamleleri de aynı şekilde örnekleyerek devasa sayıda simülasyon harcarsınız. Eric'in buradaki çerçevesi keskin: klasik MCTS her action'ı geniş bir bandit üzerinde uniform prior gibi ele alır. 10 kollu bir bandit için bu fena değildir. 361 kollu ve 300 seviye derinliğinde iç içe geçmiş bir bandit için umutsuzdur.
2. PUCT ve prior neden oyunun tamamıdır?
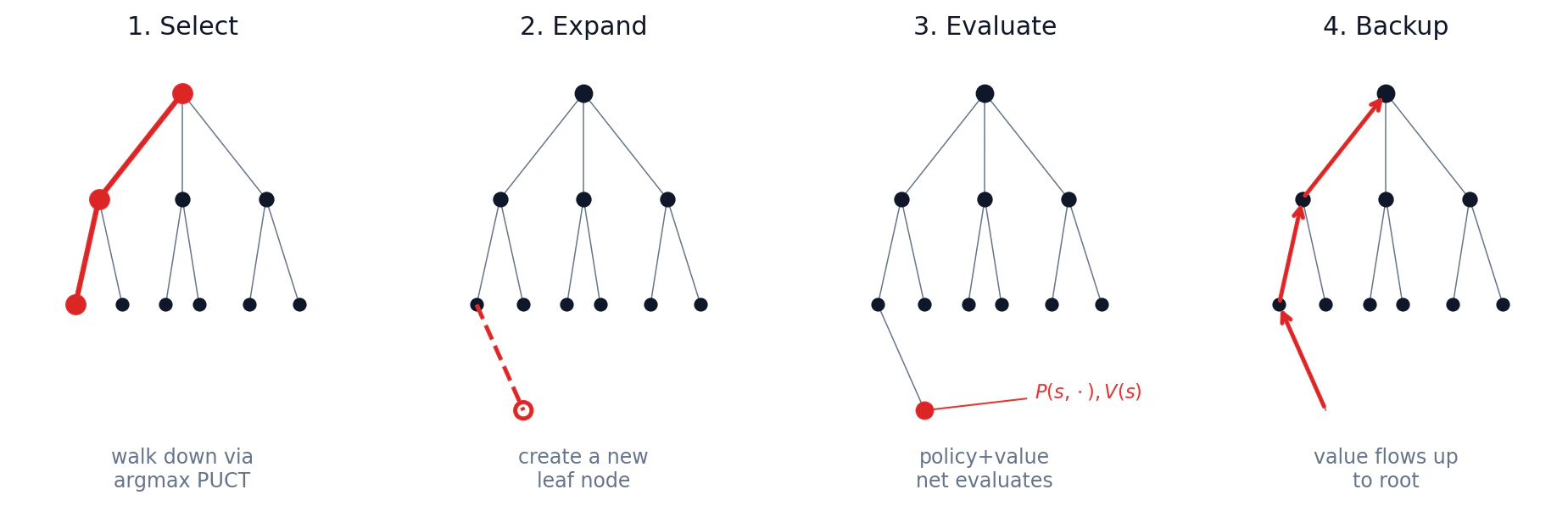
AlphaGo'nun ilk büyük değişikliği, UCB1'i PUCT (Predictor + Upper Confidence applied to Trees) ile değiştirmektir:

Yeni terim
Yeni bir node'a ilk ziyarette
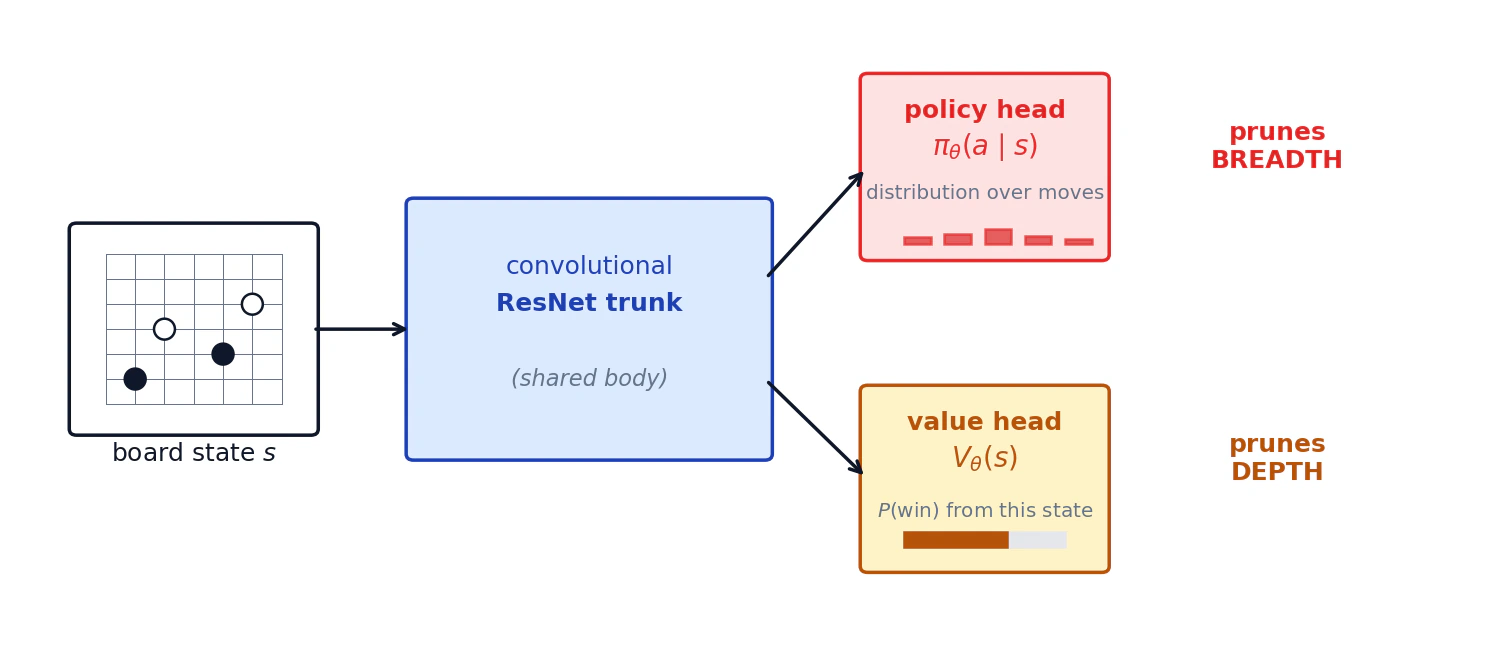
Sıfırdan eğitilen bir Go botunda prior, hangi hamlelerin bariz aptalca olmadığına dair search-time bilgisinin neredeyse tamamını taşır. Value head ise aramayı ne zaman durduracağınızı söyler. İyi bir prior olmadan MCTS yine 361 hamlenin tamamına yayılır ve search depth asla yönetilebilir hale gelmez. Bu bölüm genişliği çözüyor; derinliği ise network'ün ikinci çıktısı olan value head çözüyor.
3. İki başlı network
Eric'in söylediği gibi: insanlar tahtaya bakar ve oyun bitmeden 100 hamle önce kazanma olasılığını içgüdüsel olarak hesaplar. Bir neural network bu hesabı amortize edebilir; 100 hamlelik rollout yerine tek bir forward pass koyabilir. Value head'iniz olduğunda leaf'e kadar simüle etmek zorunda kalmazsınız. Terminal olmayan herhangi bir state'te durur ve value head'in tahminine güvenirsiniz.
AlphaGo'nun neural network'ü bir board state alır ve iki şey üretir:
- Policy head,
: iyi action'lar üzerinde olasılık dağılımı. Genişliği budar. - Value head,
: bu state'ten kazanma olasılığı. Derinliği budar.
Doğal bir soru şu: policy head gerçekten gerekli mi? Eğer
İkinci, daha mimari bir soru da şu: Alanın geri kalanı Transformer'lara geçmişken neden convolutional ResNet? Eric kendi ölçeğinde Transformer'ları denedi ve ResNet'leri geçemedi. Okuması şu: Go savaşları, yani capture'lar, ladder'lar, life-and-death problemleri yoğun biçimde lokaldir. Convolutional receptive field'lar "bu taşın yakınında ne olduğu en önemli şeydir" öncülünü kodlar ve faydalı bir lokal pattern tahta boyunca yeniden kullanılır. Daha büyük ölçeklerde Transformer'ların bu inductive bias'ı veriden öğrenebileceğini düşünüyor, ama kendi bütçesinde CNN prior kazandı.
Son olarak, network sadece mevcut tahtayı görür, geçmişi görmez. Go perfect-information bir oyundur ve yalnızca
4. Self-play ve neyin damıtıldığı
Network ve PUCT elinizde olduğunda eğitim döngüsü basittir. Her self-play oyunundaki her hamle için agent
Belirli bir root'tan tüm
Eğitim de buffer üzerinde supervised learning'den ibarettir:
Bu kadar. Advantage estimation yok, TD (Temporal Difference) learning yok, PPO (Proximal Policy Optimization) yok, off-policy importance weight yok. Sadece MCTS visit distribution'a karşı cross-entropy loss ve oyun sonucuna karşı MSE loss; ağırlıkları zevkinize göre ölçekleyebilirsiniz.
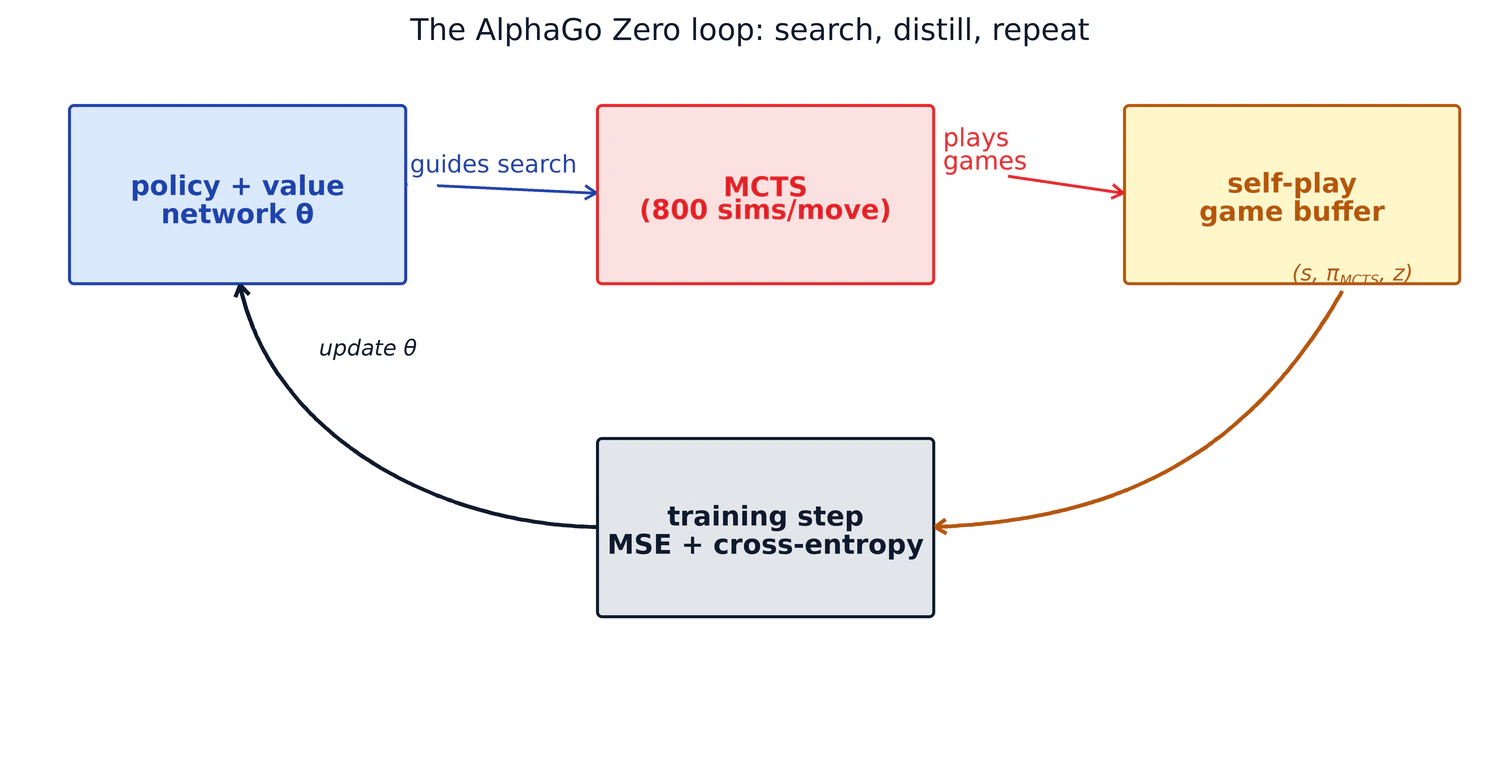
Birçok turdan sonra policy network, gördüğü her state'te MCTS'nin hesaplayacağı şeyi içselleştirmiş olur. Network'ten geçen forward pass'ler tek başına search distribution'a giderek yaklaşır. Bu, bir sonraki MCTS turunun daha keskin bir prior ile başladığı anlamına gelir; search daha verimli olur; visit distribution daha da keskinleşir.
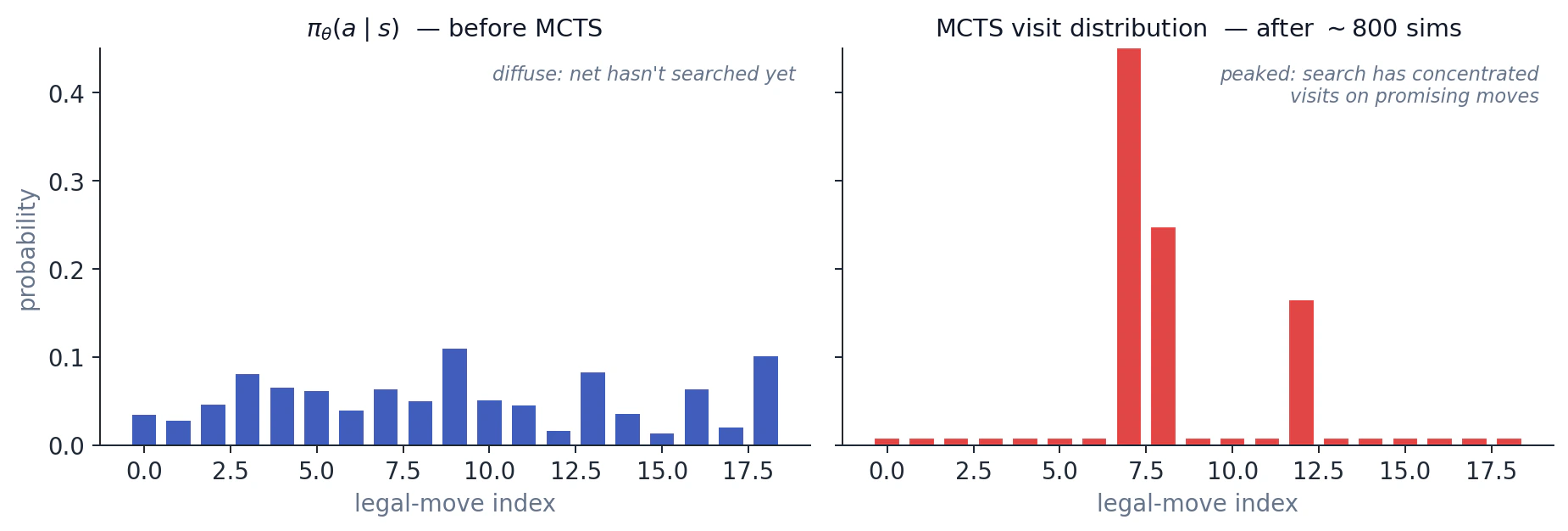
Bunun naif winner-imitation'dan neden çok daha iyi olduğunu görebilirsiniz. MCTS ile damıtılmış policy, sadece kazanıp kazanmadığınızı öğrendiğiniz terminal pozisyonlarda değil, her state'te search'ten faydalanır. Aşağıdaki win-rate curve'leri kazancı gösteriyor: inference'ta tek bir forward pass ve hiç MCTS olmasa bile, MCTS hedefleriyle eğitilmiş bir network yalnızca oyun sonuçlarıyla eğitilmiş olandan çok daha güçlüdür. Inference'ta MCTS'yi tekrar üstüne koyduğunuzda bir artış daha alırsınız.
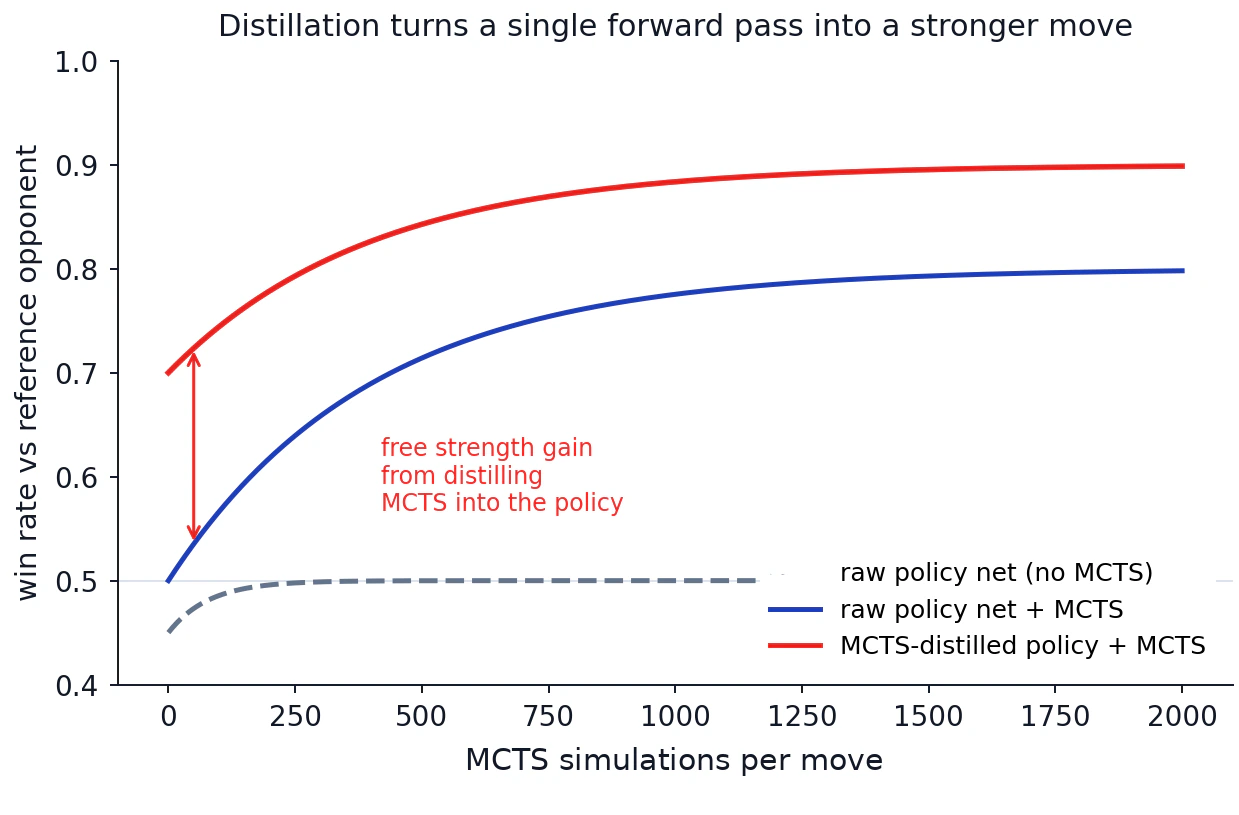
Kesikli çizgi, hiç MCTS kullanmayan ham policy network'tür. Mavi çizgi, üstüne MCTS eklenmiş aynı network'tür. Kırmızı çizgi, MCTS hedefleriyle damıtılmış ve inference'ta yeniden MCTS ile kullanılan network'tür. Sıfır MCTS simülasyonunda bile damıtılmış network çok daha güçlüdür. Distillation, search'ü forward pass'in içine paketlemiştir.
Eric ders boyunca AlphaGo'ya birkaç kez "zarif" diyor. Kastettiği şey bu. Her zaman supervision sinyalinin temiz ve yoğun olduğu bir rejimde çalışırsınız, çünkü MCTS ziyaret ettiğiniz her state'te size daha iyi bir label verir; sadece kazanca götüren az sayıdaki state'te değil. Podcast'in sonlarına doğru söylediği gibi: AlphaGo'da "non-zero success rate'e nasıl ulaşırım" şeklindeki exploration problemini çözmek zorunda kalmazsınız. Her adım güzel bir supervised signal üzerinde hill-climb'dır.
5. Naif REINFORCE neden plateau yapar?
AlphaGo/MCTS distillation'ın neden özel olduğunu görmek için ders, neyin çalışmadığına sapıyor. MCTS'yi tamamen atlayıp sadece naif policy-gradient self-play yaptığınızı varsayın: policy checkpoint'lerinden oluşan bir ligi birbirine karşı oynatın, bir tarafın kazandığı oyunları bulun ve o oyunlardaki action'ları reinforce edin.
Eric'in örneği şöyle: iki denk policy 300 hamlelik 100 oyun oynuyor. Şans eseri biri 51'e 49 kazanıyor. Bu 51 galibiyetin yalnızca birinin gerçekten daha iyi bir hamleden geldiğini, diğer 50'sinin istatistiksel gürültü olduğunu düşünün. Naif REINFORCE update'i kazanan her oyundaki her action'ı yukarı ağırlıklandırmak ister. Böylece yaklaşık 30.000 gürültülü label'ın içine gömülü tek faydalı gradient elde edersiniz.
Variance matematiği:
burada
İşaret etmeye değer bir düzeltme. Podcast'te Eric kuadratik büyümeyi policy gradient'in multi-step formülasyonuna bağlıyor ve LLM lab'lerinin single-step RL'i bu yüzden tercih ettiğini söylüyor. Kayıttan sonra errata yayımladı: variance, gradient'i full sequence üzerinden de formüle etseniz per-token da formüle etseniz, sequence length ile kuadratik büyür. Hatta per-token reward'larınız varsa multi-step RL'in variance'ı single-step'ten daha düşüktür. LLM lab'lerinin single-step yapmasının gerçek sebebi, sadece sequence-level reward'lara sahip olmalarıdır: kod geçti mi, cevap yardımcı oldu mu? Bu yüzden per-token formülasyon size aynı şeyi verir. Çıkarım şu: uzun sequence'lerde credit assignment worst case'te kuadratik zordur; blowup'a sebep olan şey formülasyon seçimi değildir.
MCTS'nin farklı yaptığı şey, credit-assignment problemini tamamen kenardan dolaşmaktır. "Bu oyun kazanıldı, bu hamleleri kopyala" demek yerine MCTS şunu der: "Ziyaret ettiğin her state'te, oynadığından daha iyi bir hamle burada." Ziyaret edilen her state yoğun bir supervision target olur. Sinyali gürültüden kazıp çıkarmanız gerekmez.
Klasik RL variance düzeltmeleri, yani advantage estimation
6. MCTS, NFSP ve iki yönde search
Ziyaret edilen her state'e daha iyi bir action atamanın tek yolu MCTS değildir. Bir diğer seçenek de DeepMind'ın AlphaStar'ında ve OpenAI Five'da çok etkili kullanılan Neural Fictitious Self-Play (NFSP)'dir.
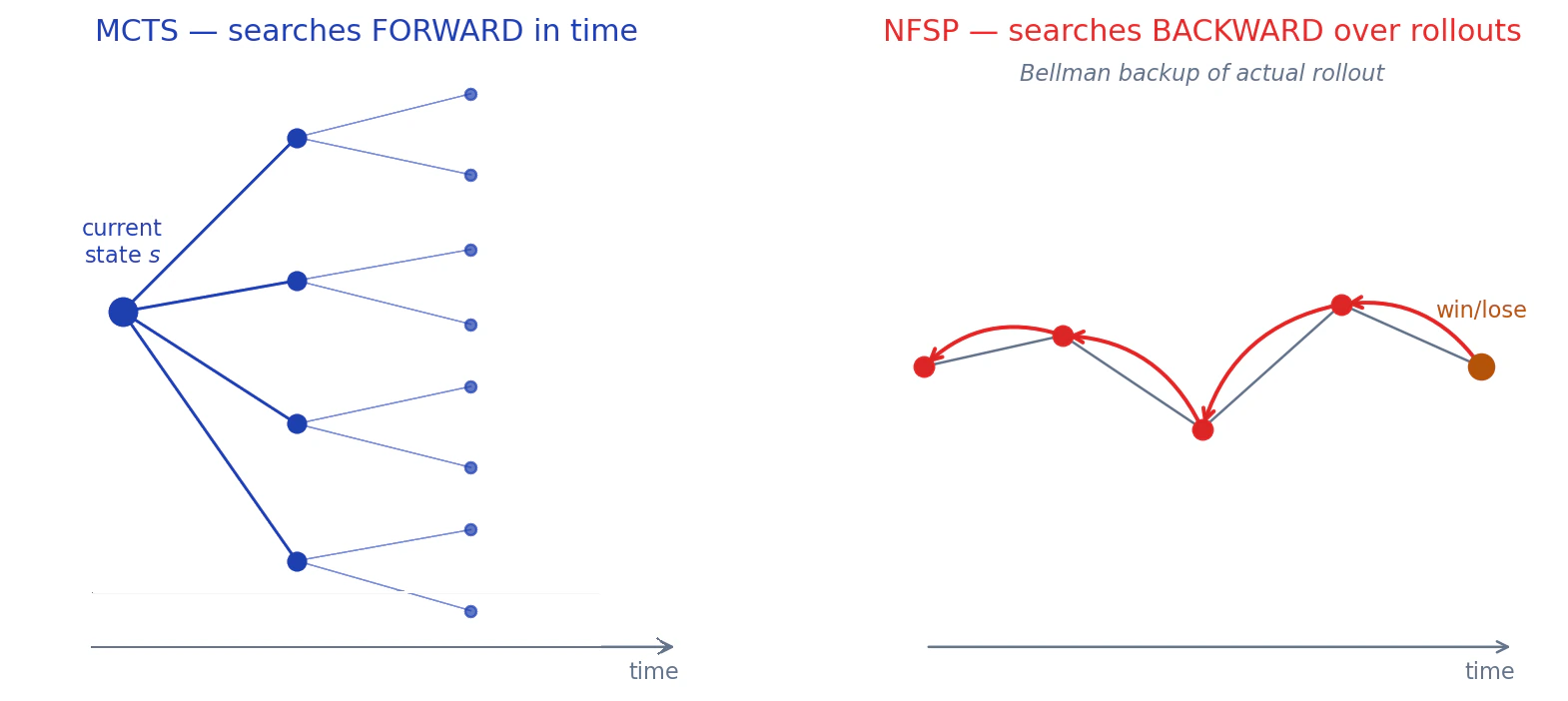
NFSP'de bir opponent
MCTS ve NFSP aynı şeyi üretir: replay buffer'daki her state
MCTS hayal edilen trajectory'ler üzerinde ileri doğru search yapar; NFSP gerçekleşmiş trajectory'ler üzerinde geriye doğru search yapar
Tarif şudur: buffer'ınızdaki her state'i search ile iyileştirilmiş bir action'la etiketleyin ve bunun üzerinde supervise edin. Go'da bunu yapmanın en ucuz yolu MCTS'dir, çünkü oyun fully observable'dır ve ileri doğru simüle edebilirsiniz. Imperfect-information oyunlarında NFSP aynı şeyi geriye doğru başarır.
7. MCTS neden LLM'lere aktarılmıyor?
DeepSeek-R1 makalesi, LLM reasoning için MCTS'yi çalıştıramadıklarını bildirdi. Eric'in teşhisi iki yapısal başarısızlık belirliyor:
Sınırsız genişlik. Go'da ply başına en fazla 361 legal hamle vardır. "Reasoning trace'te olası bir sonraki düşünce" uzayı ise fiilen sınırsızdır. PUCT'nin
Derinlik sınırsızdır ve value head'i eğitmek zordur. Go'da
Bunlardan birini telafi edebilirsiniz. İkisini aynı anda telafi etmek çok daha zordur. İnsanlar çeşitli Tree-of-Thoughts varyantlarıyla bunu denedi. PUCT, Go'nun boyutuna ve derinliğine göre ayarlanmış bir sezgiseldir. Dilin kombinatoriğine zarif biçimde ölçeklenmez.
Bugünkü LLM'lerde çalışan şey, açık bir tree yapısı olmadan reasoning'e benzeyen bir şeydir: modeller bir yaklaşım dener, çalışmadığını fark eder, geri çekilir, başka bir yaklaşım dener. Bu açıkça inşa edilmekten çok eğitimden çıkmıştır. Eric, LLM reasoning'de forward search'ün geri dönme ihtimalini dışlamıyor; sadece muhtemelen token'lar üzerinde PUCT olarak değil. MuZero tarzı yöntemler continuous control'de hala zorlanıyor.
Konuşmadan ilgili bir dipnot: 2021'de Andy Jones, Scaling Scaling Laws with Board Games'i yayımladı. Bu çalışma MCTS güdümlü board game'lerde training compute ile test-time compute'un öngörülebilir oranlarda takas edilebildiğini gösterdi. Bu, daha sonra o1 sınıfı reasoning modelleriyle popülerleşen test-time scaling paradigmasının, beş yıl önce bir Go botu üzerinde görülmüş haliydi. Ama sorun şu: scaling law'lar ancak alttaki tarif çalışmaya başladıktan sonra ortaya çıkar. Data'nız kötüyse veya mimariniz yanlışsa, scaling law'lar size kendinden emin ama yanlış extrapolation verir. Eric autogo'ya kısmen scaling law'larla güçlü bir Go botuna Bitter-Lesson tarzı yol alıp alamayacağını görmek için başladı. Dürüst cevabı: yapamazsınız, çünkü önce scaling law'ların fit edeceği datayı üretecek çalışan bir sisteme ihtiyacınız var.
8. Off-policy training ve DAgger
AlphaGo Zero'nun pratikte daha şaşırtıcı yönlerinden biri, replay buffer'ının fiilen off-policy olması ve buna rağmen çalışmasıdır. Gradient step yaptığınız zamana gelindiğinde, batch'teki çoğu (state, action) çifti policy'nin eski versiyonları tarafından üretilmiştir. RL araştırmacıları normalde bunun için endişelenir; off-policy bilinen bir instability kaynağıdır.
Defterimde tanımları şöyle netleştirdim:
- Off-policy, agent'ın action'ları üreten policy'den farklı bir policy'yi değerlendirip iyileştirerek optimal strategy öğrenmesi demektir. Başka policy'lerin, ya da geçmiş benliklerin, yaptıklarından öğrenir. Q-learning, deep deterministic policy gradient ve soft actor-critic klasik off-policy yöntemlerdir. Sample-efficient ve exploratory'dirler, ama unstable olabilirler.
- On-policy, agent'ın yalnızca mevcut policy'sinin ürettiği action'lardan öğrenmesi demektir. PPO bunun kanonik örneğidir.
AlphaGo Zero'daki bilmece şu: off-policy replay buffer neden stable?
Cevap DAgger'dır (Dataset Aggregation; Stéphane Ross'un imitation learning çalışmasından). On-policy imitation learning'in failure mode'u, yalnızca optimal trajectory'nin state'leri üzerinde eğitilmenizdir. İlk kez yoldan saptığınızda training data'nızın kapsamadığı bir state'e düşersiniz ve hatalar birikir. DAgger training set'i, off-optimal state'leri sizi geri hunileyecek expert action ile etiketlenmiş halde ekleyerek büyütür.
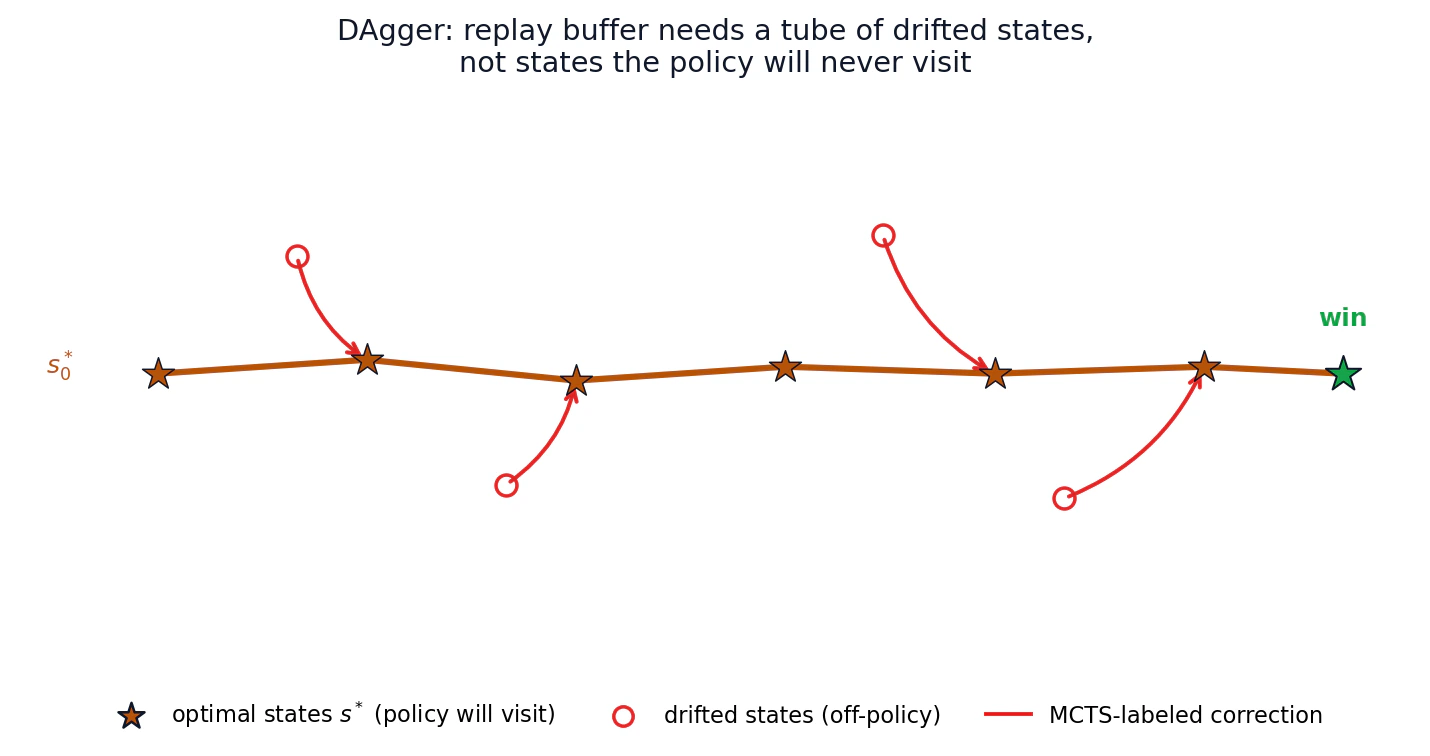
AlphaGo'nun replay buffer'ı doğal bir DAgger dataset'idir. Buffer'daki state'ler çoğunlukla policy'nin tipik trajectory'leri üzerindedir, arada biraz drift vardır. Buffer'daki her state, tanımı gereği kazanmaya doğru işaret eden MCTS türevi bir label taşır. Bu yüzden eski state'leri örneklediğinizde bile supervision network'e winning trajectory manifold'una doğru huni oluşturmayı öğretir.
Bunu bozacak failure mode, buffer'ın mevcut policy'nin asla ziyaret etmeyeceği state'lerle dolu olmasıdır. O zaman actual play için ilgisiz state space bölgeleri üzerinde eğitim yaparsınız. AlphaGo-Zero tarzı sistemler bunu fresh self-play data karıştırarak kontrol altında tutar.
Eric autogo'da bunu daha ileri götürdü: bir self-play oyununun her hamlesinde MCTS yapmak yerine, rastgele board state'leri örnekleyip her birinde mevcut network ile MCTS'yi yeniden çalıştırdığı bir deney yaptı. Bu, robotics'teki off-policy setup'a çok daha benzer; bir Bellman updater sürekli "bu state'te ne yapmalıydım?" diye yeniden düşünür. Çalışır. MCTS label'ları rastgele board state'lerinden bile winning play'e geri huniler.
Bu aynı zamanda AlphaGo ile modern robotics off-policy learning arasındaki en güçlü bağlantıdır. QT-Opt ve benzeri sistemler tam olarak bunu yapar: bir pusher transition'ları replay buffer'a yazar, bir Bellman updater sürekli
9. RL düşündüğünüzden daha bilgi-verimsizdir
Podcast'in en alıntılanabilir bölümü Dwarkesh ve Eric'in bits per sample üzerine konuştuğu yer. RL hakkındaki standart endişe sample inefficiency'dir: herhangi bir sinyal almak için bütün bir trajectory rollout etmeniz gerekir. Agent'lar çok günlük task'lara girdikçe FLOP başına sample sayısı düşmeye devam eder.
Daha az takdir edilen problem bits per sample'dır. Eğitilmemiş bir LLM'in "the sky is..." prompt'u ile karşılaştığını ve vocabulary size'ın 100K olduğunu düşünün. Supervised learning altında size cevabın "blue" olduğu söylenir ve cross-entropy loss'unuz
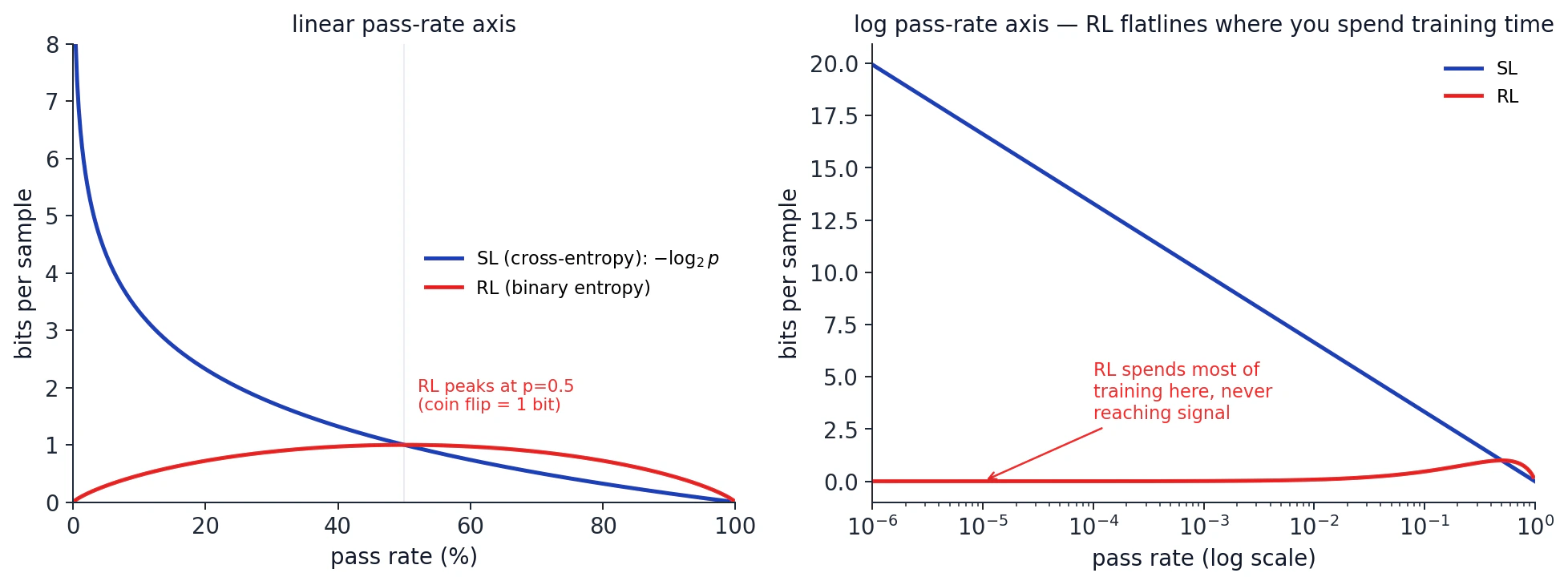
Formel olarak: pass rate
Bu ifade
AlphaGo döngüsünün özel olmasının en derin sebebi bu. Her supervision step'i tek bir en iyi hamleye one-hot değil, visit distribution üzerinde soft target'tır. Soft target'lar sample başına one-hot label'lardan çok daha fazla bilgi taşır: dark-knowledge distillation argümanı budur. Bu yüzden AlphaGo'nun policy network'ü her adımda sample başına maksimum bit alır. MCTS mevcut policy'den kesin biçimde daha iyi bir labeler olduğu için supervision sinyali asla düzleşmez.
Podcast'ten hatırlanacak cümle: AlphaGo'da policy network'ü MCTS action'ını taklit etsin diye eğitmezsiniz; MCTS distribution'ını taklit etsin diye eğitirsiniz. Action one-hot'tır; distribution yoğundur. Dark knowledge budur.
Bunun çalışması için üç şeyin aynı anda doğru olması gerekir: value function ucuz ve somut olmalı, action space PUCT'nin davranabileceği kadar küçük olmalı, hızlı bir simulator olmalı. Go'da üçünün üçü de var. Coding, multi-step reasoning ve ekonomik değeri yüksek task'ların çoğunda üçte sıfır var.
10. Bu automated AI research için ne anlama geliyor?
Podcast'in kapanış bölümü algoritmalardan research workflow'a dönüyor. Eric autogo için coding agent'ları yoğun biçimde kullandı. Dürüst raporu şu: bugünkü frontier modeller, yol tanımlandıktan sonra hill-climbing'de iyi. Bir hyperparameter sweep çalıştırabilir, bazı layer'larda gradient'ların küçük olduğunu fark edebilir, code change önerebilir, experiment çalıştırabilir ve follow-up önerebilirler. Buna sabit bir objective üzerinde "grad-student-like" execution diyor.
Henüz yapamadıkları ve Eric'in tekrar tekrar çarptığı şey lateral thinking. Mevcut yol yanlış olduğunda, metric plateau yaptığında, infra'da ince bir bug olduğunda ya da problemin framing'i yanlış olduğunda, modeller first principles'a geri çekilmek yerine yanlış eksende öğütmeye devam eder. Gerçek research insight genelde insanın "dur, bu deney dalının tamamı yanlış bir varsayımdan çıkıyor" diye fark etmesinden gelir.
Bu, AlphaGo dersinin tersidir. AlphaGo çalışır çünkü MCTS policy network'e her state'te daima daha iyi bir öğretmen verir. Mevcut LLM coding agent'larının böyle bir öğretmeni yoktur. Bir reward'ları vardır, yani test geçti mi, ve gürültülü ara seçimlerle dolu uzun bir horizon'ları vardır. Eric'in iki saat boyunca anlattığı yüksek-variance, düşük-bits-per-sample rejimindedirler.
Rebuild-AlphaGo egzersizinden tek bir çıkarım istiyorsanız, bence şu: bir agent'a per-state öğretmen vermeyi çözmek, yani MCTS'nin "oynadığından kesinlikle daha iyi bir action burada" eşdeğerini bulmak, sparse terminal reward'lar üzerinde RL'i ölçeklemekten muhtemelen daha yüksek kaldıraçtır. Bu öğretmenin forward search'ten mi, backward TD'den mi, daha güçlü bir modelden distillation'dan mı, yoksa henüz icat etmediğimiz bir şeyden mi geleceğini bilmiyoruz. Ama AlphaGo tarifi neyin eksik olduğunu çok net gösteriyor.
Eric Jang ve Dwarkesh Patel'e teşekkürler.
Eric'in etkileşimli AlphaGo tutorial'ı kanonik referanstır; tüm kod GitHub'daki autogo reposunda. Policy-gradient variance üzerine errata'sı kısa ve okumaya değer.