Frontier LLM'ler Nasıl Eğitiliyor ve Sunuluyor
Yayınlanma tarihi 2026-05-0321 dk okuma4,010 kelime Lisans CC BY-NC-SA 4.0 artificial intelligencecomputer sciencewritingpersonal İçindekiler

Bu yazı, Reiner Pope'un Dwarkesh Patel ile yaptığı kara tahta tarzı röportajdan aldığım el yazısı notlara, ayrıca yayınlanan transkript ve Dwarkesh'in bu podcast bölümü için hazırladığı flashcard'lar ile yaptığım çapraz kontrollere dayanıyor.
Bunu videoyla birlikte, bir çalışma rehberi gibi açmanızı öneririm.
Bazı röportajlar sohbet gibidir. Reiner Pope'un Dwarkesh ile yaptığı bölüm ise pek sohbet sayılmaz; bütün AI ekonomisinin nasıl çalıştığının, tek bir kara tahtaya sıkıştırılmış bir özeti gibi.
Bu yazı boyunca aşağıdaki soruların cevaplarını öğreneceksiniz.
- Neden "Slow Mode" ayrı bir ürün olarak yok?
- Neden MoE katmanları doğal biçimde bir rack'e denk düşüyor?
- Neden pipeline parallelism inference tarafında aslında çok şey kazandırmıyor ve Ilya neden bunun akıllıca olmadığını söyledi?
- Neden frontier modeller Chinchilla optimumunun yaklaşık 100 katı ötesinde over-trained ediliyor?
- Gemini 3.1 neden 200K context üstünde %50 daha fazla ücret alıyor ve output token'ları neden input token'larından 5 kat pahalı?
Bölüm 1: Batch size token maliyetini ve hızı nasıl etkiler?
Öncelikle matematikten korkmayın. Burada tek bir ana fikir var. Bir modeli çalıştıran çip aynı anda iki şey yapıyor: hesaplama yapıyor ve veriyi hareket ettiriyor. Bunlardan biri her zaman bottleneck oluyor. Her birinin ne kadar sürdüğünü yazabilirseniz, geri kalan neredeyse her şeyi tahmin edebilirsiniz.
Bütün ders tek bir eşitsizlik üzerine kurulu:
t, bir forward pass için geçen süre.
t compute ve t mem terimleri şöyle açılıyor:
B, batch size; başka bir deyişle tek bir forward pass sırasında canlı olan sequence sayısı. "Kullanıcı" değil. "Eş zamanlı oturum" değil. Model aynı matmul'u (matrix multiplication) bir kez çalıştırdığı anda uçuşta olan sequence'ler. N_active, aktif parameter count, yani token başına gerçekten kullanılan çarpanlar. N_total, total parameter count; yani HBM'de (High bandwidth memory) duran ve içeri çekilmesi gereken her şey.
Compute terimi attention'ın kendisini ihmal ediyor; bu, bilinçli bir sadeleştirme. Memory teriminde iki alt terim var: weight fetch için sabit bir terim ve KV-cache fetch için hem batch hem context uzunluğuyla lineer artan bir terim. KV cache = B x length of context x bytes per token.
mem_bw = memory bandwidth
Bu yazıdaki geri kalan her şey bu denklemlerden çıkıyor.
Latency curve
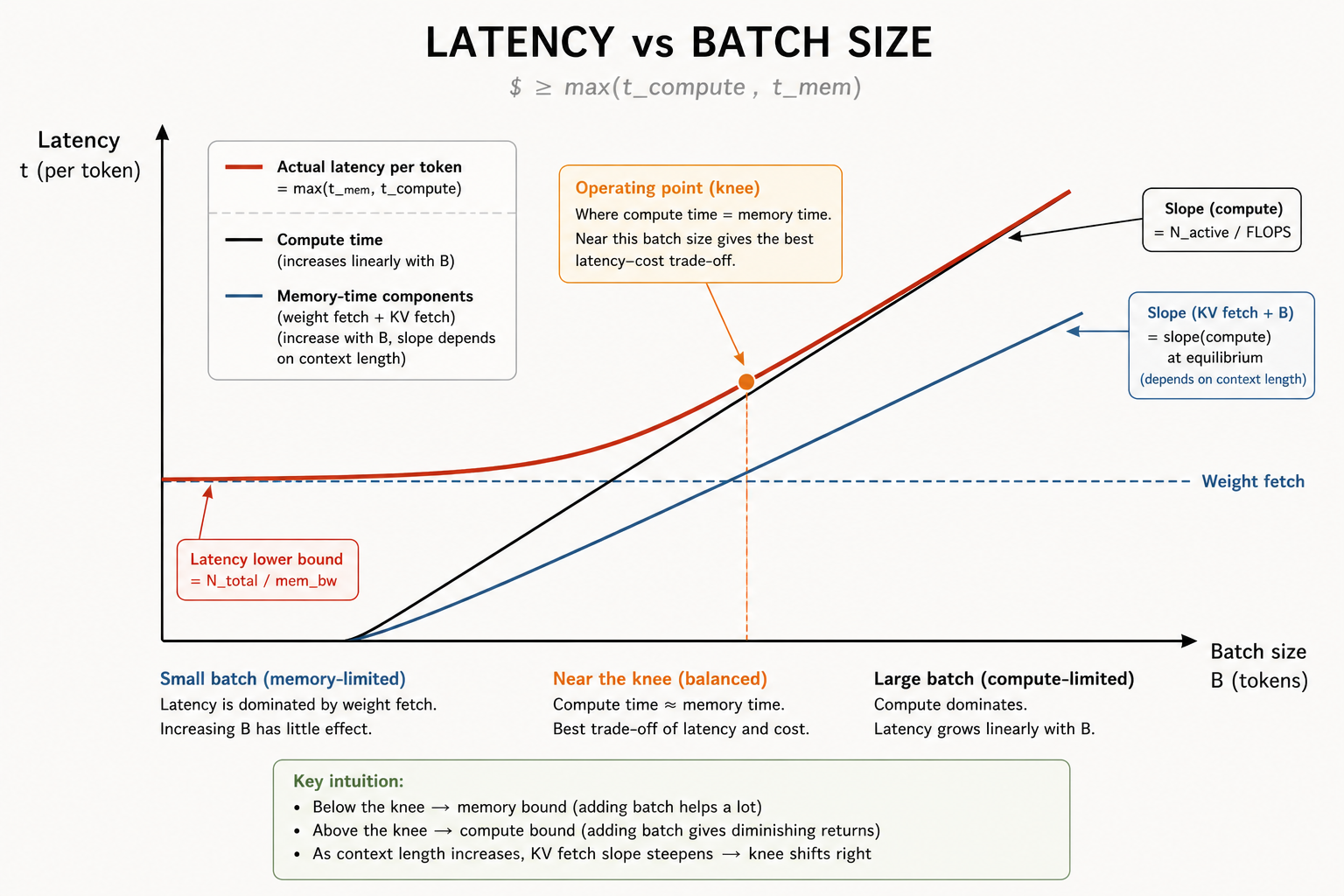
- Compute orijinden başlayarak lineer büyür.
- KV fetch de
Bile lineer büyür, ama eğimi context length ve bytes per token tarafından belirlenir. - Weight fetch düz bir sabittir;
N_total / mem_bw. Kaç sequence'in birlikte yolculuk ettiğini umursamaz.
Gerçek latency, memory terimlerinin toplamı ile compute teriminin maksimumudur. Grafikte kalın kırmızı çizgi budur: küçük batch'lerde memory curve'e sarılır, sonra compute bottleneck olduğunda compute curve'e devreder.
Bu grafikten çıkan iki sonuç:
1. Sert bir latency zemini vardır. Bu zemin N_total / mem_bw değeridir. Bütün weight'leri HBM'den compute unit'lere bir kez sürüklemek için gereken süreden daha hızlı servis veremezsiniz. Bu temel alt sınırdır ve LLM'lerde "Slow Mode"un ayrı bir ürün olarak gerçekten var olmamasının nedeni budur. Sağlayıcılar rekabetçi kalmak için zaten mümkün olduğunca ucuza servis veriyor ve çoğu bunun üstüne inference'ı sübvanse ediyor.
2. Crossover hedef noktadır. t_KV eğimi t_compute eğimiyle eşleştiğinde aynı anda hem memory-bound hem compute-bound olursunuz. Bu noktanın iki tarafında da silikon boşta kalır. O kesişimi yakalamak operasyonel sweet spottur.
Latency'den cost'a: Cost-per-token grafiği
Cost, latency'den farklı bir sorudur. Müşteri süre için ödeme yapmaz; servis edilen token'lara yayılmış rental second'lar için ödeme yapar. Bu yüzden her curve'ü B'ye böleriz:
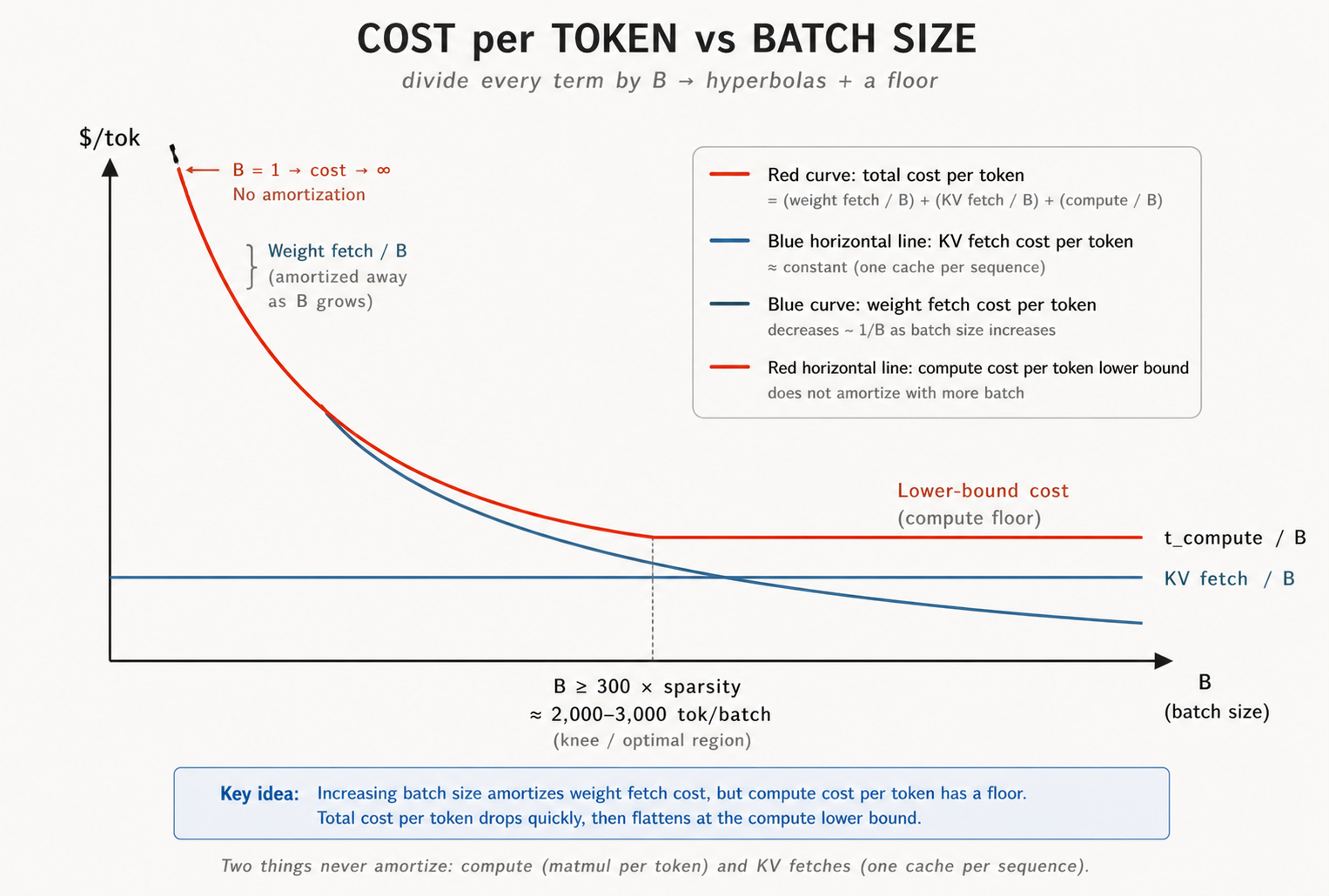
- Compute curve lineerdi -> düz hale gelir.
- KV fetch lineerdi -> o da düz hale gelir.
- Weight fetch sabitti -> hiperbole dönüşür ve
Bbüyüdükçe hızla düşer.
B = 1 olduğunda cost sonsuza gider; tek bir token bütün weight fetch yükünü omuzlar. Büyük B değerlerinde weight fetch'ler amortize olur ve cost compute floor'a çöker.
İki şey asla amortize olmaz: compute, çünkü her token kendi matmul'unu alır; KV fetch, çünkü her sequence kendi context'ini getirir.
Optimal batch size'i çözmek
Şimdilik KV'yi yok sayarak t_compute ile t_mem içindeki weight-fetch kısmını eşitleyelim:
Donanımı bir tarafa, modeli diğer tarafa alalım:
FLOPS / mem_bw oranı şu soruyu sorar: Saniyede hareket ettirebildiğiniz her byte memory için çip saniyede kaç matematik işlemi yapabiliyor?
Blackwell GPU'da yaklaşık olarak:
- FLOPS ≈ saniyede 4.500 trilyon FP4 multiply
- mem_bw ≈ saniyede 8 trilyon byte
- Her FP4 weight yarım byte
Yani çip, memory bandwidth'ün her byte'ı için yaklaşık 4,500 / 8 ≈ 560 multiply yapabilir. Ama her FP4 weight sadece yarım byte olduğu için 560 × 0.5 ≈ 280. Yuvarlayınca ~300. Bu sayı A100 -> H100 -> B100 boyunca pek değişmedi; FLOPS ve bandwidth birlikte ölçeklendi.
O halde:
DeepSeek V3 için token başına 256 expert'in 32'si aktif, yani N_total/N_active = 8; bu da B ≥ 300 × 8 = 2,400 verir. Pratikte operatörler bunun 2-3 katı yüksek çalıştırır, çünkü gerçek verimlilik roofline'ın gerisinde kalır. Yuvarlak sayı: 2.000-3.000 token taşıyan 20 milisaniyelik bir tren.
20 milisaniyelik tren
Neden özellikle 20 ms? Çünkü HBM drain time, yani capacity divided by bandwidth, neredeyse her modern HBM generation'da 20 ms'dir. Rubin generation'da bu yaklaşık ~288 GB / ~20 TB/s ≈ 15 ms'ye daha yakın.
Bu neden önemli? Çünkü 20 ms içinde HBM'in tamamını tam olarak bir kez okuyabilirsiniz. Bir pass içinde iki kez okumak istemezsiniz; weight matrix'leri read-only'dir ve KV cache'inizi yeniden fetch etmek istemezsiniz. Bu yüzden 20 ms doğal cycle time'dır.
Bir "tren" her drain-time'da kalkar. Tren geldiğinde hazır olan sequence'ler biner. Tren dolarsa kalanlar bekler. Yarı boşsa yine de kalkar. Worst-case queueing latency: ~40 ms. Kaçırdığınız ilk tren, artı bir sonraki trene binme süresi.
Concurrent users değil, tokens per second
"Concurrent users" bulanık bir kavramdır; tokens per second ise nettir:
Gemini'nin bildirilen trafiği global ölçekte saniyede yüz milyonlarca token seviyesinde. Yani optimal batch'lenmiş tek bir serving cell, Gemini load'unun yaklaşık binde birini taşır. Bu da şu demek: ticari olarak rekabet etmek için Gemini trafiğinin en az binde birine sahip olmanız gerekir. Bunun altında treni bile dolduramazsınız.
Bölüm 2: MoE modeller GPU rack'lerine nasıl yerleştirilir?
İşte bir mixture-of-experts (MoE) katmanı:
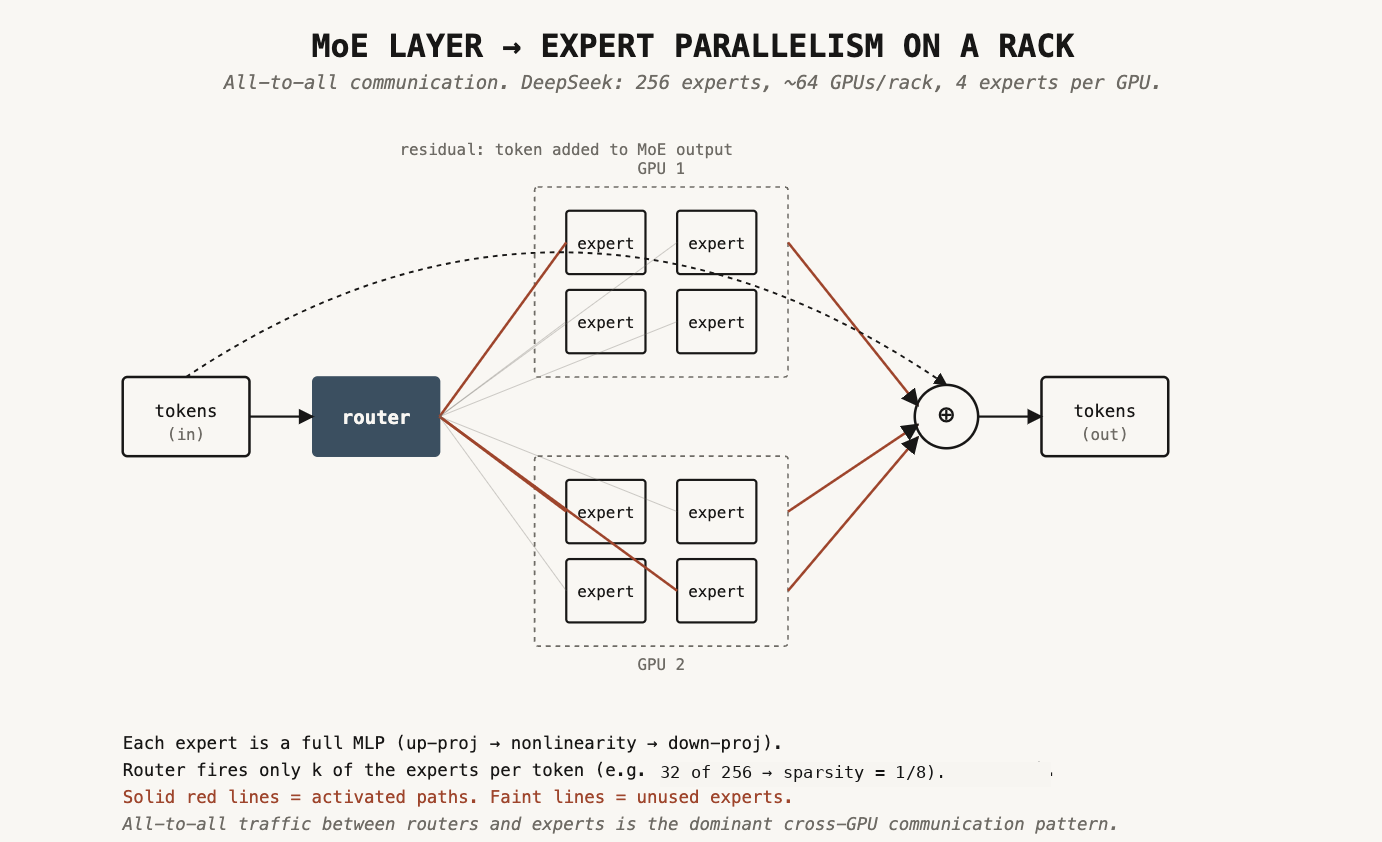
Token'lar içeri girer, router token başına E expert'ten k tanesini aktive eder; burada E katmandaki toplam expert sayısı, k ise her token için çalışan expert sayısıdır (DeepSeek: 256'nın 32'si). k/E oranına sparsity deriz.
Her expert tam bir MLP'dir (multi-layer perceptron). Basitçe söylemek gerekirse sırayla üç şey yapar: "genişlet → düşün → sıkıştır".
1. Up-projection: Token'ın vector'ünü uzun bir matrix ile çarpar ve çok daha yüksek boyutlu bir alana genişletir. Token 4.000 boyutlu bir vector ise up-proj onu 16.000 dimension'a çıkarabilir.
2. Nonlinearity: ReLU, GELU veya SwiGLU gibi bir fonksiyonu element-wise uygular. Bunlar farklı activation function'lardır ve şimdilik görmezden gelinebilir. Katmanın gerçekten non-trivial function'lar hesaplayabildiği yer burasıdır; nonlinearity olmadan üst üste iki matrix multiplication sadece tek bir matrix multiplication'a çökerdi.
3. Down-projection: Başka bir matrix ile vector'ü yeniden orijinal dimension'a, mesela 4.000'e, indirir. Sonuç artık input ile aynı shape'tedir ve bir sonraki katmana akabilir.
Seçilen expert'lerin output'ları toplanır ve bu toplam residual stream'e eklenir.
Somutlaştırırsak:
new_token = old_token + MoE(old_token)
old_token, residual stream'dir; modelin baştan sona içinden akan running vector. MoE(old_token) bu katmanın yaptığı katkıdır. Her attention ve MLP katmanı residual stream'i okur ve katkısını geri ekler. Modelin final cevabı, bütün katmanlar yazdıktan sonra residual stream'den okunur.
Standart yerleşim expert parallelism'dir: farklı expert'ler farklı GPU'lardadır. DeepSeek'te 256 expert var; bir Blackwell rack'inde 72 GPU var (bölünebilirlik için 64 kullanın, diğer sekizi yok sayın). Bu GPU başına 4 expert demek. Routing böylece all-to-all traffic pattern'e dönüşür: herhangi bir GPU'daki token, herhangi bir GPU'daki expert'e gönderilebilir.
Bu yüzden tek rack doğal bir sınırdır. Rack içinde NVLink/NVSwitch her GPU'yu diğer tüm GPU'lara full bandwidth ile bağlar; all-to-all için mükemmel bir eşleşme. Rack dışına çıktığınızda scale-out network'e düşersiniz ve bandwidth yaklaşık 8 kat azalır.
Scale-up vs scale-out
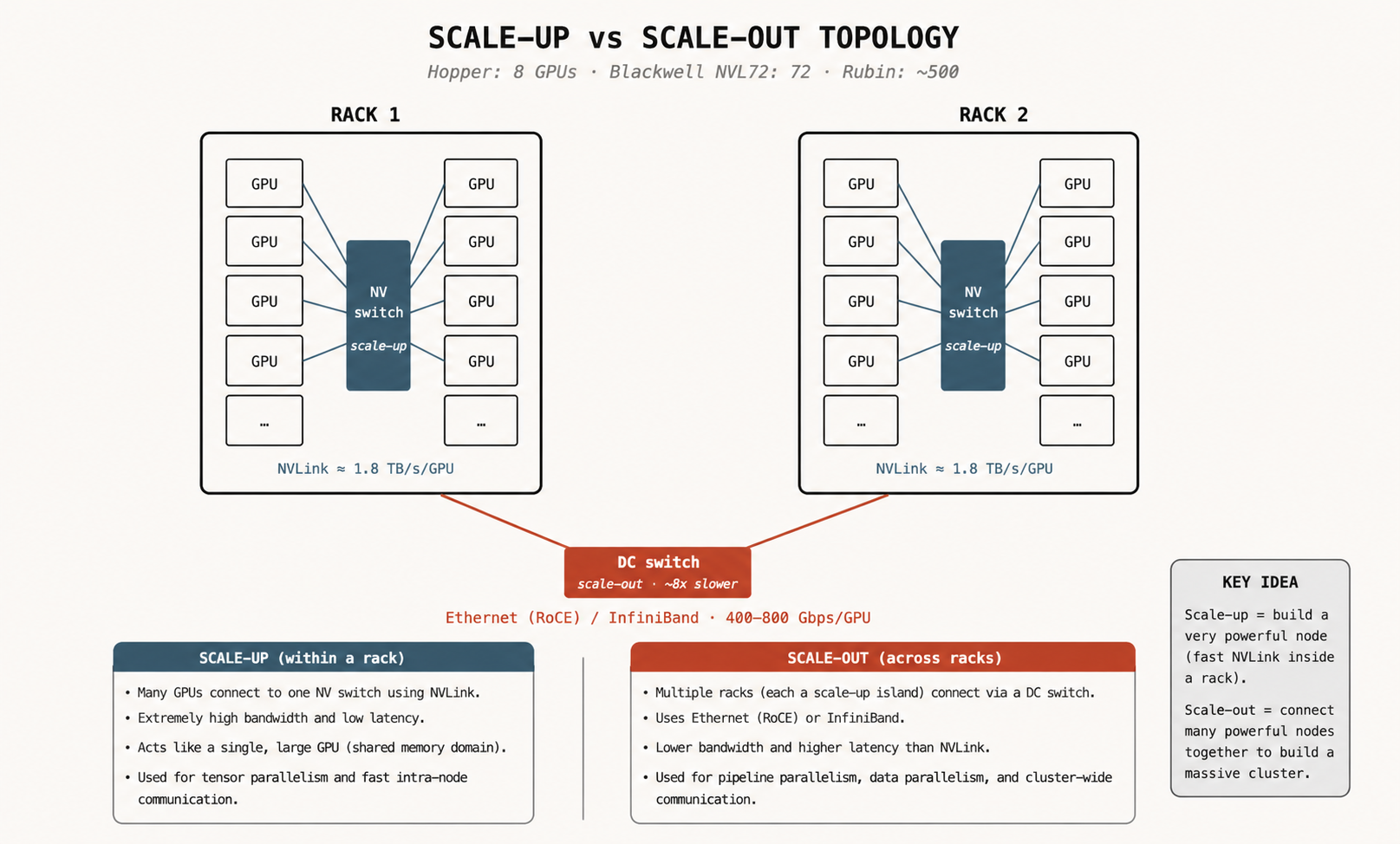
Üç sağlayıcı, aynı şey için üç isim:
| Sağlayıcılar | Scale-up (rack içi) | Scale-out (rack arası) |
|---|---|---|
| NVIDIA | NVLink / NVSwitch | Ethernet (RoCE) / InfiniBand |
| AMD | Infinity Fabric | Ethernet / InfiniBand |
| Inter-Chip Interconnect (ICI) | Ethernet |
Scale-up bandwidth'leri GPU başına multi-TB/s aralığındadır ve latency yüzlerce nanosaniye seviyesindedir. Blackwell NVLink yaklaşık 1.8 TB/s/GPU'dur. Scale-out ise GPU başına 400-800 Gbps'dir; Blackwell için rack içi ile dışı arasında yaklaşık 3 kat, genel bandwidth karşılaştırmasında yaklaşık 8 kat fark vardır.
NVIDIA GPU'ları veriyi doğrudan bir GPU'dan diğerine gönderebilir.
TPU'lar farklı route eder: TPU'lar belirli bir hedefe ulaşmak için pod içindeki tüm TPU'lardan geçmek zorundadır. TPU v4'ten (2021) başlayarak Google, TPU block'ları arasına Optical Circuit Switches ekledi; bunlar hangi block'ların fiziksel komşu olduğunu job başına dinamik olarak yeniden yapılandırır.
Scale-up domain'leri neden büyümeye devam ediyor?
| Generation | GPUs in scale-up | Form factor |
|---|---|---|
| Hopper | 8 | Tray |
| Blackwell | 72 | Rack |
| Rubin | ~500 | Rack (çok daha yoğun) |
Hopper'dan Blackwell'e geçiş çoğunlukla bir ürün kararıydı: tray'den rack'e geçmek. Blackwell'den Rubin'e geçiş ise daha agresif cable routing ve power delivery sayesinde kabaca 4 kat density artışı. Bir rack'i sınırlayan şey power, weight, cooling ve kabloların bend radius'udur. Modern rack'ler bunların her birini fiziksel sınıra kadar iter.
Makro sonuç, "model size'ları neden ancak yakın zamanda tekrar ölçeklenmeye başladı?" sorusunun cevabıdır. GPT-4'ün 2023'te trilyon civarı parameter'a sahip olduğu söylentisi vardı. Anlamlı ölçüde daha büyük modeller ise ancak son altı ayda çıkmaya başladı. Kısıt algoritma değildi; scale-up domain yeterince büyüyüp multi-trillion-param bir modeli ve binlerce sequence için KV cache'i ekonomik olarak barındırabilecek hale gelene kadar bunu servis edemezdiniz.
Active parameters compute cost tarafından sınırlanır. Total parameters scale-up size tarafından sınırlanır.
Google'ın erken avantajı da bu denklemdeydi: TPU pod'ları yıllardır büyük scale-up domain'lere sahipti.
Bölüm 3: Pipeline parallelism, micro-batching ve bubble
Expert parallelism tek bir MoE katmanını halleder. Bir modeli tek rack'ten daha derine uzatmak için pipeline parallelism'e başvurursunuz: layer 1 rack 1'de, layer 2 rack 2'de, böyle devam eder. Tensor parallelism, yani hidden dimension veya FFN (Feed-Forward Network) dimension boyunca kesmek, prensipte üçüncü bir seçenek. Ama expert'ler artık küçük olduğu için bu matematik artık çalışmıyor. Tensor-parallel kesimler her transformer block içinde sık all-reduce / all-gather operation'ları zorlar; dimension'lar çok büyük ve interconnect çok hızlı değilse communication overhead kazanımı yer.
Buna karşılık layer parallelism ve expert parallelism, modeli kendi içinde kapalı computational unit'lere böler; her device konuşmadan önce anlamlı iş yapar. Layer'lar ve expert'ler transformer'ın "chunky" dimension'larıdır ve chunky kesimler daha iyi compute-to-communication ratio verir.
Pipelining scale-up'a ne zaman zarar verir?
Scale-up time ile scale-out time oranını kuralım. Scale-up'ın dominate etmesini isteriz, çünkü değerli resource odur:
2 ile çarpma, all-to-all up ve all-to-all down içindir.
Üç pozitif terimin çarpımının 8 kat bandwidth penalty'yi yenmesi gerekir. Tek başına activated expert sayısı çoğu zaman 8'dir. Birkaç layer per pipeline stage ekleyince rahatça barajın üstüne çıkarsınız.
Yani: rack'leri pipeline ile bağlamak forward pass için iyidir; all-to-all communication rack içinde kalır, rack sınırlarını sadece residual stream geçer.
Inference: Bubble yok

Inference'ta backward pass yoktur. Her rack kendi layer'ını çalıştırır; token'lar ileri akar; bir rack batch 0'ı bitirdiği anda batch 1'i alır. n_micro_batches = n_pipeline_stages yaparsanız wraparound pürüzsüz olur. Bubble yok. Latency açısından bu neutraldır; layer'lar tek rack'te de yaşasa dört rack'te de yaşasa full forward pass aynı süreyi alır, çünkü pipeline stage'ler tek bir inference için sırayla çalışır. Pipelining sadece rack başına memory capacity kazandırır.
Training: Bubble kaçınılmaz
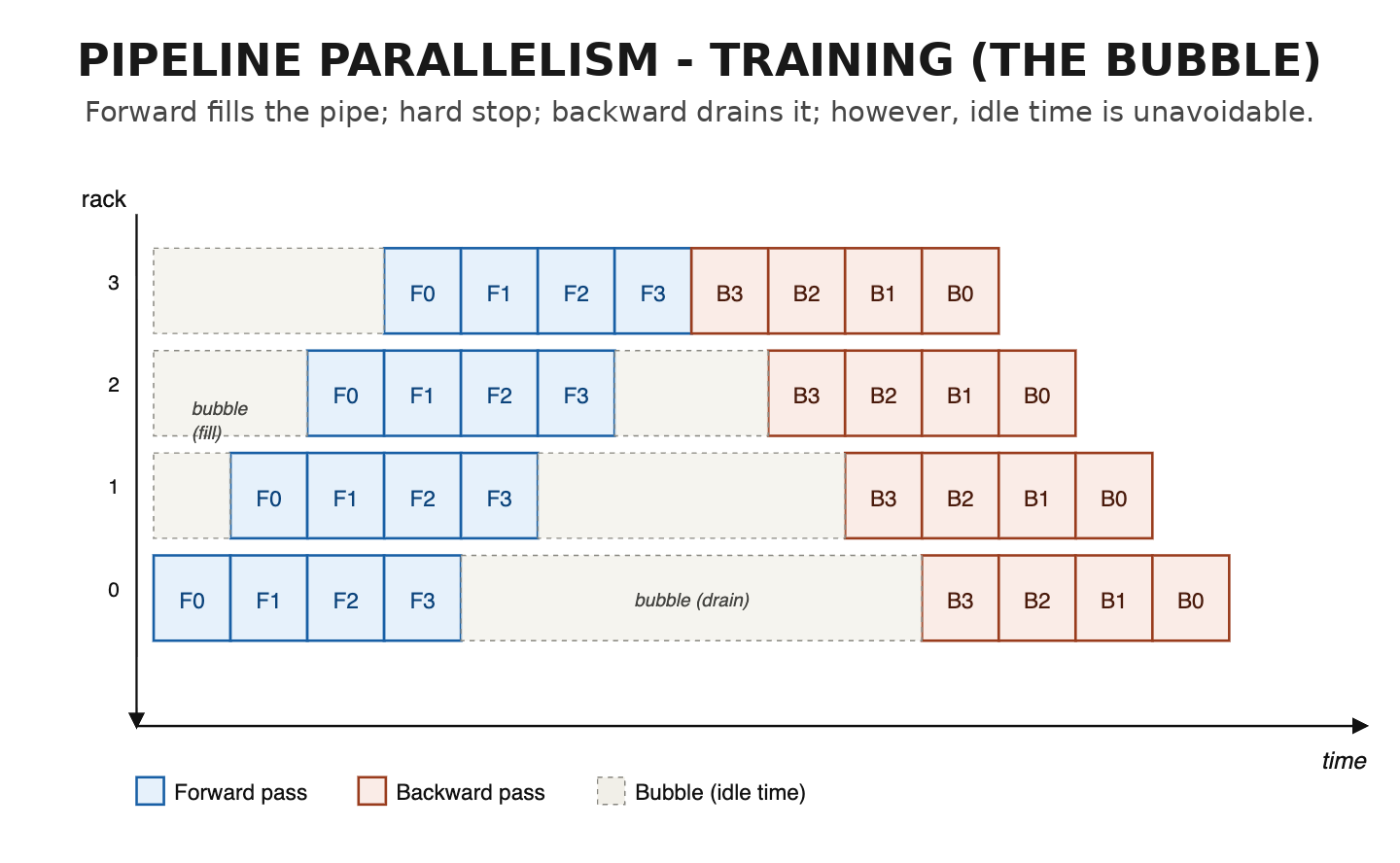
Training'de pipeline'ın önce dolması, sonra boşalması gerekir. Forward pass boruyu doldurur; sonra sert bir duruşa çarparsınız (F3 ile B3 arasında), çünkü backward tüm batch'in gradient'ine aynı anda ihtiyaç duyar; sonra backward pass boruyu boşaltır. Taranmış bölgeler bubble'dır: boru dolar veya boşalırken rack'ler hiçbir şey yapmaz.
Neden sert duruş var? Çünkü ML convergence için optimal batch size vardır (küçük batch'ler daha taze gradient verir) ve buna rakip olan total training time için optimum vardır (küçük batch'ler systems açısından kötüdür). Seçilen batch size bu ikisinin arasında bir yerdedir ve trade-off buradan doğar. Batch seçildikten sonra tamamını forward, sonra tamamını backward yaparsınız; bubble'ı yaratan şey de budur.
Bölüm 4: Ilya neden "As we now know, pipelining is not wise" dedi?
Pipeline bubble için akıllı workaround'lar var; zero bubble ve one-forward-one-backward denen schedule'lar yönleri iç içe geçirerek rack'leri meşgul tutar. Ama meşhur Ilya cümlesinin çarptığı yer burası: "As we now know, pipelining is not wise."
Memory capacity rack başınadır. Modeliniz sığmıyorsa pipelining onu rack'lere bölmenizi sağlar. Ilya'nın meşhur cümlesi, bunun biriktirdiği architectural debt ile ilgilidir. Kimi'nin residual-attention'ı gibi yaklaşımlar — her block'un birden fazla önceki layer'ın residual'ına attend ettiği yapılarda — bu residual'ların aynı yerde bulunduğunu varsayar; residual'lar farklı stage'lerde yaşadığında bunu uygulamak çok zorlaşır. Interleaved sliding-window ve global attention layer'ları load imbalance yaratır. Her kısıt research iteration'ı yavaşlatır ve frontier lab'de bu büyük bir günahtır.
Daha büyük memory equation
Sistem başına total memory:
GPU başına, E = expert parallelism (örneğin 64) ve P = pipelining (örneğin 4 rack) ile:
İkinci terimin denominator'ında sadece E olduğuna dikkat edin, E · P değil. P'ler birbirini götürür. Nasıl ve neden? Pipelining, P rack'in her birinin weight'lerin farklı bir parçasını tutmasını sağlar. Weight footprint rack başına P kadar düşer. Ama her rack, meşgul kalmak için slot'unda aynı anda P farklı sequence tutmak zorundadır; micro-batching bunu yapar. Bu yüzden KV-cache footprint rack başına micro-batch yüzünden P ile çarpılır ve cache'in stage'ler arasında sharding edilmesi yüzünden P'ye bölünür. Net sonuç sıfır.
Çünkü B = n_micro · b ve n_micro = P; pipeline'ı dolu tutmak için uçuşta bu kadar micro-batch gerekir. Pipelining GPU başına weight footprint'i küçültür ama KV cache footprint için hiçbir şey yapmaz. P ≥ 2 olduğunda KV cache GPU başına dominant memory bottleneck haline gelir.
Bu tam olarak DeepSeek'in V3 inference için yayınladığı reçetedir ve frontier lab'ler muhtemelen bunu yapıyor. Tek bir scale-up domain içinde expert parallelism'i maksimize et ve çok az pipelining kullan. Frontier inference muhtemelen tek bir scale-up üzerinde çalışıyor.
Daha büyük scale-up'ın gizli bandwidth kazancı
Scale-up'ın capacity'den bile daha önemli olmasının başka bir nedeni var:
Buradaki mem_bw, weight'leri paralel şekilde yükleyen tüm GPU'ların aggregate memory bandwidth'üdür; yani (scale-up size) × (per-GPU BW). Per-GPU bandwidth her generation'da yaklaşık ~1.5-2 kat büyüdü. Scale-up size ise Hopper'dan Blackwell'e 8 kat büyüdü. Latency improvement'ın çoğu daha hızlı HBM'den değil, weight yükleyen daha fazla HBM port'una sahip olmaktan geldi.
Daha büyük scale-up, daha düşük latency inference sağlar ve bu da daha uzun context length'leri mümkün kılar. Hala KV-fetch term tarafından sınırlıyız; sparse attention kalite pahasına yardımcı olsa da memory wall'u kırmaz. Son iki yılda context length'lerin 100-200K civarında plato yapmasının bir nedeni de budur.
Bölüm 5: Reinforcement learning ve Chinchilla'nın ötesinde over-training
6ND sayısı nereden geliyor?
Training cost için her tahmin, Chinchilla'nınki, GPT-4'ünki, scaling-law paper'lardaki herhangi bir tahmin, aynı formülden geçer: 6ND; burada N active parameters, D training tokens. 6'nın nereden geldiği şöyle.
Tek bir multiply-add için forward pass, parameter başına token başına 2 FLOPs'tur (bir multiply + bir add). Backward pass, forward pass'in 2 katıdır; matrix multiplication'da hem input matrix'lere göre gradient hesaplarsınız. Yani backward için parameter başına token başına 4 FLOPs, toplamda 2 + 4 = 6.
Üç bucket, tek cost equation
Model yaşamının üç stage'i boyunca total compute cost:
RL coefficient 2-6 arasındadır; rollout'ların her birinde backward-pass yapıp yapmadığınıza bağlıdır. Inefficiency factor, RL rollout'larında ve inference'ta kullanılan decode'un prefill veya saf training'e kıyasla çok daha düşük MFU (Model Flops Utilization) ile çalıştığını hesaba katar.
Equality heuristic
Trade-off yapan maliyetlerde bir terim büyür, diğeri küçülür. Minimum çoğu zaman iki terimin eşit olduğu yerde oturur. Sezgi şudur: başka herhangi bir noktada bir tarafta, diğer tarafta tasarruf ettiğinizden daha fazla ödeme yaparsınız; yani bedava hareket alanı vardır.
Hızlı örnek: f(x) = ax + b/x minimumuna x = √(b/a) noktasında ulaşır ve burada iki terim de √(ab)'ye eşittir. Bu fikir, training cost (model size ile büyür) artı inference cost (model size ile küçülür, çünkü küçük modeller daha ucuza servis edilir) gibi, büyüyen ve küçülen terimlerin toplamına gevşek biçimde genellenir.
Buraya uygularsak: Frontier lab makul ölçüde iyi optimize ediyorsa üç bucket (pre-training, RL ve inference) şunu sağlamalıdır:
N_active sadeleşir. ineff ≈ 1/3 ile şuna ulaşırsınız:
Bu üç sayı aynı mertebede olmalıdır: pre-training token'ları, RL token'ları ve lifetime inference token'ları.
Bazı gerçek sayıları yerine koymak
- Inference: Global ölçekte ~50M tokens/s, obsolete olmadan önce 2 ay deployment. ->
D_inf ≈ 2.6 × 10¹⁴ tokens= (~200T). - Pre-training (söylenti): ~150T tokens. Aynı mertebe. Heuristic tutuyor.
- Active parameters: ~100B.
- Chinchilla optimum:
D_chinchilla ≈ 20 × N_active = 2Ttokens.
Frontier ratio: 200T / 2T = 100× Chinchilla ötesi.
Neden artık kimse Chinchilla-optimal train etmiyor?
Chinchilla, belirli bir final loss için training compute'u minimize eder. Ama production'da:
Training faturası bir kez gelir. Inference faturası bütün deployment lifetime boyunca gelir.
50 kat daha fazla data ile eğitilmiş daha küçük bir model, training-FLOP başına biraz daha kötüdür (çünkü Chinchilla optimum o constraint altında optimumdu), ama servis etmek çok daha ucuzdur. Bu yüzden over-train edersiniz.
Sonuç: Ship ettiğiniz her model, eğittiğiniz data'nın yaklaşık olarak lifetime boyunca üreteceği data'ya eşit olduğu noktada, tam olarak yeterince büyüktür. Training corpus ve output stream yaklaşık aynı boyuttadır. Bu garip ve güzel bir simetridir ve kara tahtadaki equality heuristic'in doğrudan sonucudur.
Bölüm 6: API pricing üzerinden long context memory cost çıkarmak
Bölüm 6, Bölüm 1'in farklı x-axis ile tekrar edilmesidir.
Bölüm 1'deki latency plot'u hatırlayın. Compute batch ile lineerdi, memory küçük batch'te çoğunlukla flat sonra büyük batch'te lineerdi, ve ikisinin kesiştiği bir regime transition vardı. X-axis'i context length ile değiştirin; aynı plot, sadece döndürülmüş gibi yeniden ortaya çıkar. 200K'deki crossover, farklı bir sweep variable'a uygulanmış aynı crossover'dır. API pricing bunu takip eder, çünkü Google'ın cost'ları bunu takip eder.
Gemini'de 200K crossover
Gemini 3.1, 200K context length üstünde %50 daha fazla ücret alıyor. Nedeni şu:
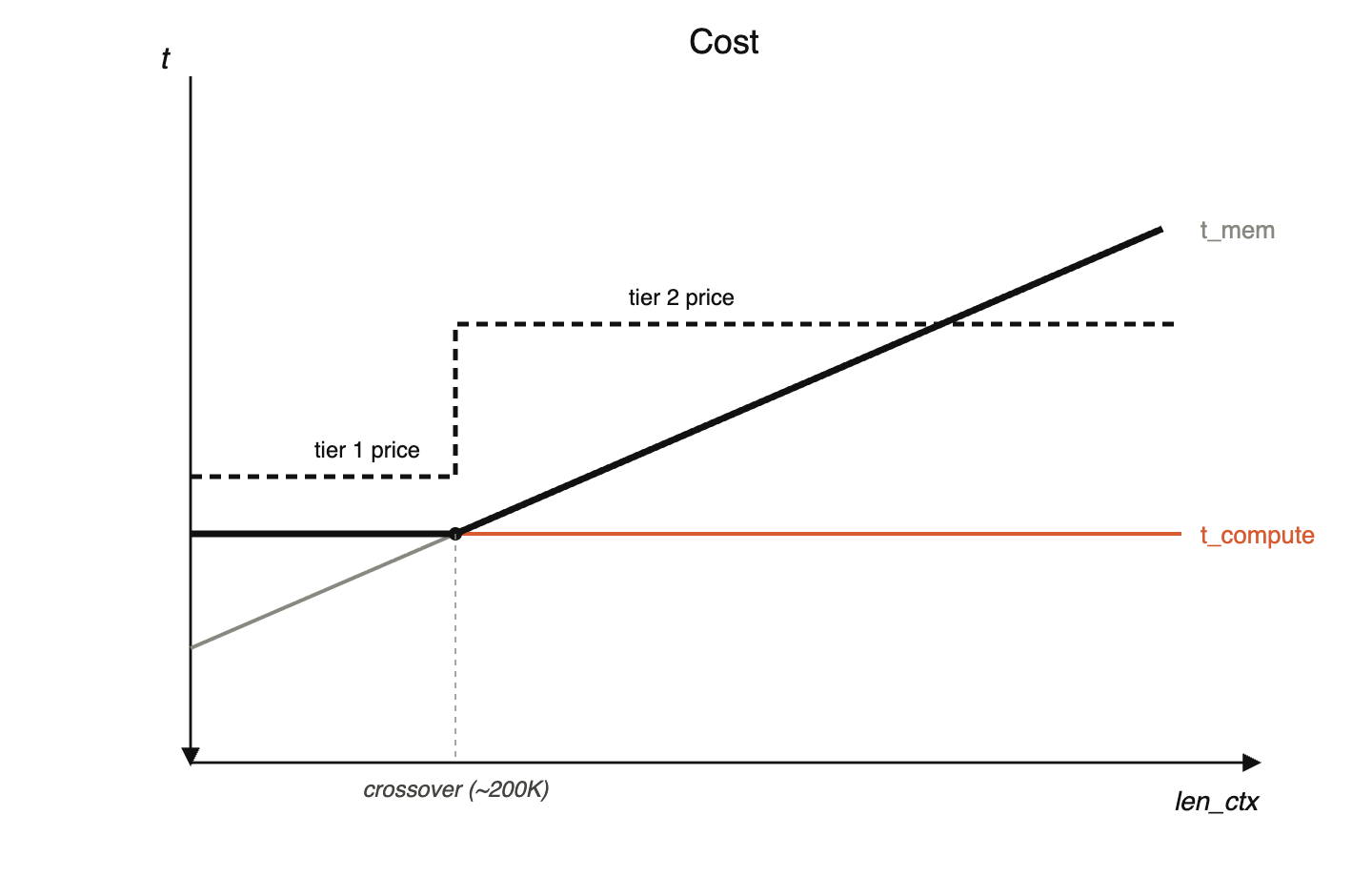
t_compute = B·N_act / FLOPS,len_ctx'e göre esasen flat'tir.t_mem,len_ctxile lineer yükselir; KV-fetch term büyür.
Pricing tier, alttaki cost envelope'u takip eder. Kink, memory time'ın compute time'ı geçtiği yerdir. Crossover'da:
Bytes per token için çözelim:
Bunu şöyle parçalayabiliriz:
d_head (dimension of the vector) = 128 ve küçük bir KV-head count (1-8) ile 1.7 KB, dense attention plus heavy cross-layer KV-cache reuse ile tutarlıdır; Character.AI / Gemma trick'inde global KV bütün attention layer'ları arasında paylaşılır. Ya da sparse attention ile. Her iki durumda da pricing architectural information sızdırmış olur.
Competitive pricing pressure her API tarifesini alttaki cost structure'ına oldukça sıkı bağlar; fiyatlarınız gerçek cost'larınızın çok üstüne çıkarsa, daha düşük cost'lu bir rakip margin'inizi yer.
Output token'ları neden input token'larından 5 kat pahalı?
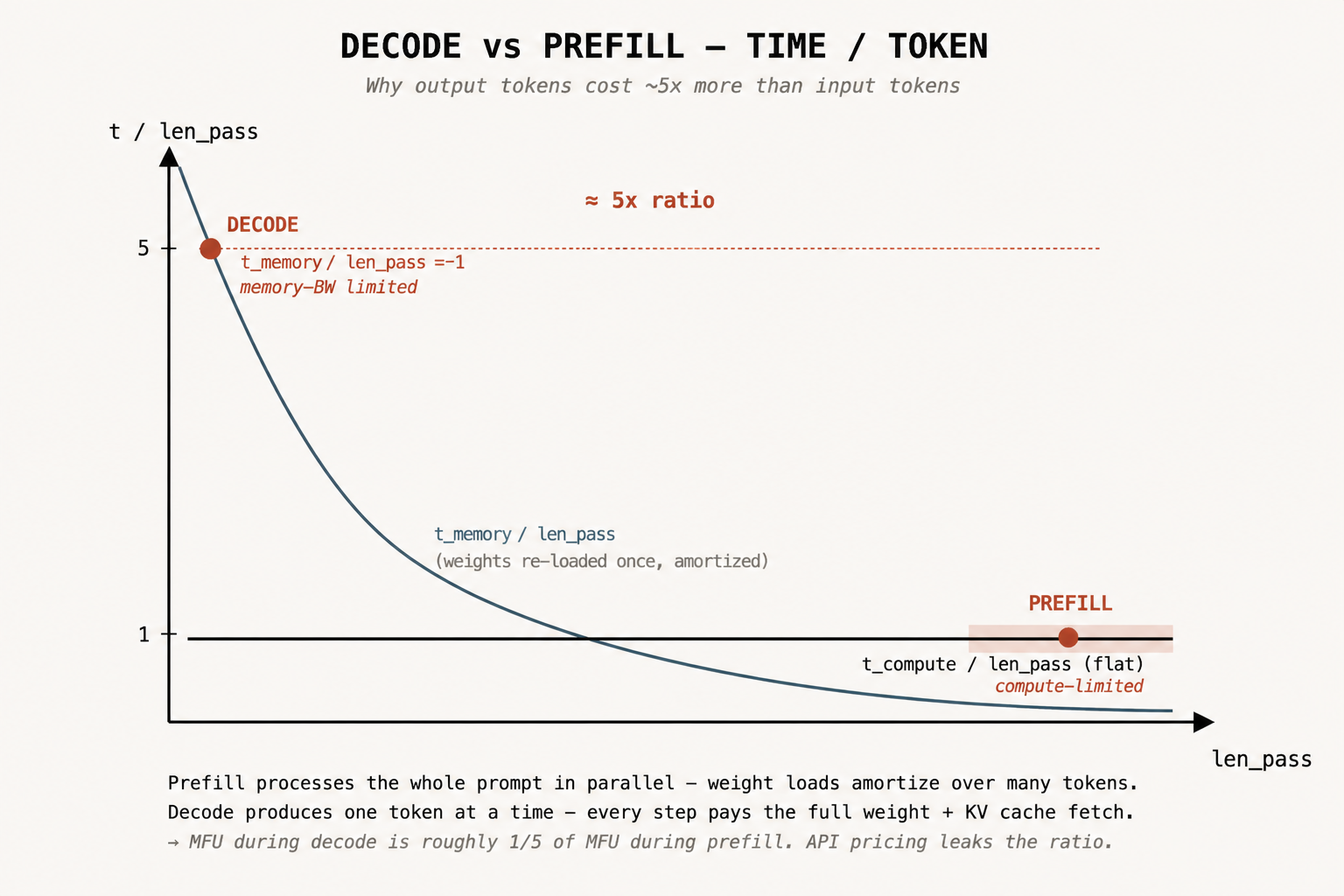
- Prefill tüm prompt'u paralel işler. Pass başına çok sayıda token. Highly parallelizable. Compute-limited.
- Decode her pass'te autoregressively tek token üretir. Her token full weights + KV cache yükler. Memory-bandwidth limited.
Time-per-token chart'ta:
t_compute / len_passflat'tir.t_mem / len_passhiperboldür.
İki regime de aynı GPU'yu aynı dolara kiralar. Değişen şey, GPU'nun FLOPS budget'ının saniye başına ne kadarının gerçekten kullanıldığıdır. Prefill FLOPS'u saturate eder, compute-bound'dur. Decode ise onları underuse eder, çünkü çip HBM beklerken boşta oturur. Pricing'deki 5 kat oran, iki regime arasındaki effective FLOPS-utilization oranıdır.
len_pass = 1 olduğunda (decode), memory dominate eder ve cost ≈ 5× olur. Büyük len_pass değerlerinde (prefill), curve compute floor'a çöker ve cost ≈ 1× olur.
Yani pricing'deki 5× oran, iki regime arasındaki MFU ratio'yu söyler. Decode, prefill MFU'sunun yaklaşık %20'sinde çalışır.
Cache hit'ler neden 10 kat ucuz?
Bir token'ın KV cache'ini materialize etmek için üç yer vardır:
| Strateji | Retrieval cost (token başına) | Hold cost (saniye başına) |
|---|---|---|
| Rematerialize (recompute) | N_act / FLOPS × GPU $/s | 0 |
| Store in HBM | ≈ 0 (zaten orada) | bytes_tok / HBM_capacity × GPU $/s |
| Store in DDR / Flash / Disk | bytes_tok / DDR_bw | bytes_tok × DDR $/s |
Optimal tier, hold time'ınızı tier'ın drain time'ına (capacity / bandwidth) eşler:
| Tier | Drain time |
|---|---|
| HBM | ~20 ms |
| DDR | ~1-10 s |
| Flash (SSD) | ~1 dakika |
| Spinning disk (HDD) | ~18-22 saat |
Bazı sağlayıcıların 5 dakikalık cache pricing VE 1 saatlik cache pricing sunması, arkadaki tier'ların flash + spinning disk olduğunu güçlü biçimde ima eder.
Million-token wall
Neden kimse million-token-context model ship etmiyor? Compute term attention içinde quadratic büyür, ama slope o kadar küçüktür ki bunu ancak multi-million token aralığında hissedersiniz. Asıl bağlayıcı constraint memory bandwidth'tir: context ile lineer büyüyen KV-fetch term.
Sparse attention lineerliği yaklaşık √len_ctx'e çevirir (DeepSeek'in önemli bir sonucu, open source'a teşekkürler). Bu büyük bir iyileştirme, sonsuz değil; sparsity'yi fazla zorlarsanız kalite çöker.
Empirically, frontier context length'ler son iki yıldır 100-200K civarında plato yaptı. Bu da bunun cost-balanced point olduğunu gösteriyor. Dario'nun continual learning'in yerini alabileceğini savunduğu türden 100M-token context'e ulaşmak için bugün var olmayan bir memory-wall breakthrough gerekir.
Bölüm 7: Okunabilir AI ekonomisi
Memory wall, bütün endüstrinin omurgası ve bottleneck'idir.
İki roofline equation'ı ve sihirli ~300 oranını içselleştirdiğinizde, AI ekonomisinin şaşırtıcı derecede büyük bir kısmı okunabilir hale gelir:
| Soru | Denklemlerin verdiği cevap |
|---|---|
| Optimal batch size? | ~300 × sparsity |
| Minimum ne kadar hızlı servis verilebilir? | N_total / mem_bw |
| Frontier modeller ne kadar over-trained? | Chinchilla'nın ~100 katı ötesinde |
| Gemini'nin KV cache'i token başına kaç byte? | ~1.7 KB |
| Output token'ları neden input'tan 5 kat pahalı? | Decode MFU ≈ 1/5 prefill MFU |
| Neden 1M-token context yok? | Memory wall'un çatısı yok |
| Yavaş storage tier'lar neden pricing'de görünüyor? | Hold time'lar her tier'ın drain time'ına eşleniyor; dakikalar için flash, saatler için disk |
| MoE katmanları neden rack'e denk düşüyor? | All-to-all NVLink topology ile tam olarak eşleşiyor |
Benim tekrar tekrar döndüğüm şey equality result: pre-training tokens ≈ inference tokens. Ship ettiğiniz her model, kabaca, eğittiğiniz data'nın lifetime boyunca üreteceği data'ya eşit olduğu noktada tam olarak yeterince büyüktür. Training corpus ve output stream yaklaşık aynı boyuttadır. Bu garip ve güzel bir simetridir ve kara tahtadaki iki heuristic equation'ın doğrudan sonucudur.
Önce ne kırılacak? Sparse attention memory wall'u kırarsa context length'ler 1M'e sıçrar. FLOPS-to-bandwidth ratio değişirse optimal batch size da onunla birlikte hareket eder.
Bu bölüm Dwarkesh'ten izlediğim favori bölümdü ve Reiner Pope bu karmaşık detayları bu kadar temiz açıkladığı için büyük övgüyü hak ediyor. Her şeyin kara tahtada serilmesi de yanında çalışmak için harikaydı. (Merak etme Dwarkesh, yeni studio yatırımı kesinlikle buna değdi.)
Neyse. Kapatmadan önce birkaç teşekkür.
Teşekkürler Dwarkesh; farklı disiplinlerden bilgi paylaşımının teşvik edildiği ve derinlemesine incelendiği bir ortam yarattığın için. Teknik ile teknik olmayan arasındaki çizgide mükemmel yürüyorsun. Bu konudaki anlayışını ve bilgisini paylaştığı için Reiner Pope'a da teşekkürler; harika bir konuşmacı ve berrak bir düşünür.